Exploratory Data Analysis (EDA) is a critical first step in any data analysis project. In this chapter, you’ll learn how to systematically explore your data to understand its structure, identify patterns, detect anomalies, and generate hypotheses for further investigation.
3.2 The Purpose of Exploratory Data Analysis
Exploratory Data Analysis serves several important purposes in natural sciences research:
Understanding Data Structure: Gain insights into the basic properties of your dataset
Checking Data Quality: Identify missing values, outliers, and potential errors
Discovering Patterns: Detect relationships, trends, and distributions
Generating Hypotheses: Develop questions and hypotheses for formal testing
Informing Analysis Choices: Guide decisions about appropriate statistical methods
PROFESSIONAL TIP: Creating Reproducible EDA Workflows
To ensure your exploratory data analysis is reproducible and transparent:
Document all data transformations: Record every cleaning step, filter, and transformation applied to raw data
Use R Markdown or Quarto: Create executable documents that combine code, output, and narrative explanation
Version control your analysis: Track changes to your EDA scripts using Git or similar tools
Save exploratory outputs: Store key visualizations and summary statistics in organized directories
Create clear data lineage: Document the origin of each dataset and how it connects to derived datasets
Use consistent naming conventions: Apply systematic naming to files, variables, and functions
Separate exploration from confirmation: Clearly distinguish exploratory analyses from confirmatory hypothesis testing
Include data validation checks: Incorporate automated checks for data integrity and quality
Provide detailed method documentation: Document statistical approaches like ANOVA types (e.g., Type II tests for unbalanced designs)
Share your EDA code: Make your exploratory scripts available alongside final analyses for complete transparency
3.3 Summarizing Data
3.3.1 Descriptive Statistics
Descriptive statistics provide a concise summary of your data’s central tendency, dispersion, and shape:
Code
# Load necessary librarieslibrary(tidyverse)# Load the crop yield datasetcrop_yields <-read_csv("../data/agriculture/crop_yields.csv")# View the first few rowshead(crop_yields)
# A tibble: 6 × 14
Entity Code Year `Wheat (tonnes per hectare)` Rice (tonnes per hectar…¹
<chr> <chr> <dbl> <dbl> <dbl>
1 Afghanistan AFG 1961 1.02 1.52
2 Afghanistan AFG 1962 0.974 1.52
3 Afghanistan AFG 1963 0.832 1.52
4 Afghanistan AFG 1964 0.951 1.73
5 Afghanistan AFG 1965 0.972 1.73
6 Afghanistan AFG 1966 0.867 1.52
# ℹ abbreviated name: ¹`Rice (tonnes per hectare)`
# ℹ 9 more variables: `Maize (tonnes per hectare)` <dbl>,
# `Soybeans (tonnes per hectare)` <dbl>,
# `Potatoes (tonnes per hectare)` <dbl>, `Beans (tonnes per hectare)` <dbl>,
# `Peas (tonnes per hectare)` <dbl>, `Cassava (tonnes per hectare)` <dbl>,
# `Barley (tonnes per hectare)` <dbl>,
# `Cocoa beans (tonnes per hectare)` <dbl>, …
Code
# Get summary statistics for wheat yieldswheat_summary <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%summarize(Mean =mean(`Wheat (tonnes per hectare)`, na.rm =TRUE),Median =median(`Wheat (tonnes per hectare)`, na.rm =TRUE),StdDev =sd(`Wheat (tonnes per hectare)`, na.rm =TRUE),Min =min(`Wheat (tonnes per hectare)`, na.rm =TRUE),Max =max(`Wheat (tonnes per hectare)`, na.rm =TRUE),Q1 =quantile(`Wheat (tonnes per hectare)`, 0.25, na.rm =TRUE),Q3 =quantile(`Wheat (tonnes per hectare)`, 0.75, na.rm =TRUE) )# Display the summary statisticsknitr::kable(wheat_summary, caption ="Summary Statistics for Global Wheat Yields")
Summary Statistics for Global Wheat Yields
Mean
Median
StdDev
Min
Max
Q1
Q3
2.434914
1.99
1.687949
0
10.6677
1.228
3.1245
Code
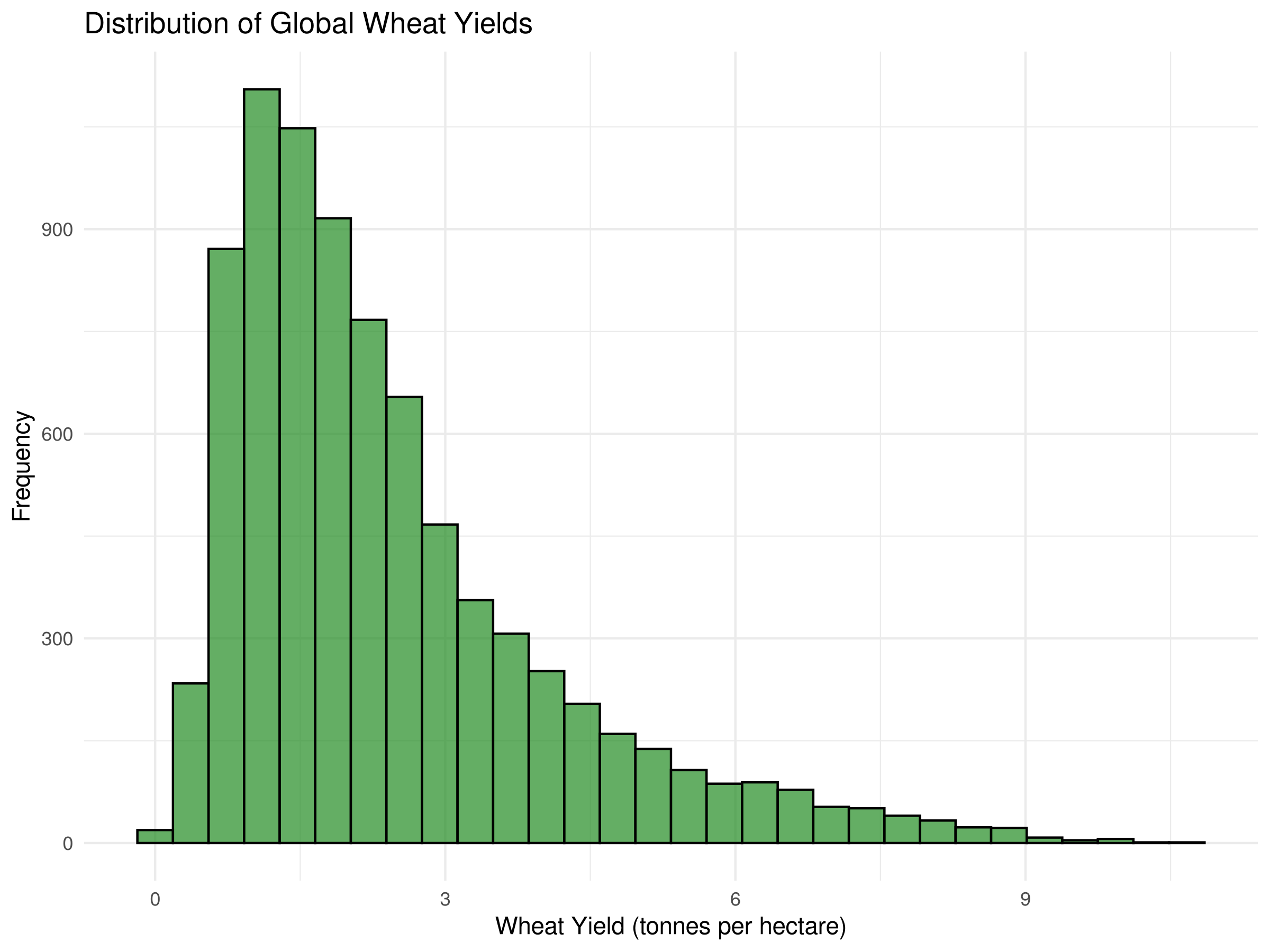
# Visualize the distribution of wheat yieldsggplot(crop_yields, aes(x =`Wheat (tonnes per hectare)`)) +geom_histogram(bins =30, fill ="forestgreen", color ="black", alpha =0.7) +labs(title ="Distribution of Global Wheat Yields",x ="Wheat Yield (tonnes per hectare)",y ="Frequency") +theme_minimal()
Code
# Identify top wheat-producing countries (by average yield)top_wheat_countries <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%group_by(Entity) %>%summarize(Avg_Yield =mean(`Wheat (tonnes per hectare)`, na.rm =TRUE)) %>%arrange(desc(Avg_Yield)) %>%head(10)# Display the top countriesknitr::kable(top_wheat_countries, caption ="Top 10 Countries by Average Wheat Yield")
Top 10 Countries by Average Wheat Yield
Entity
Avg_Yield
Belgium
8.544200
Netherlands
7.030172
Ireland
6.829840
United Kingdom
6.366400
Denmark
6.175285
Luxembourg
5.977411
Germany
5.893978
Europe, Western
5.723267
France
5.645341
Northern Europe
5.589988
Code Explanation
This code block demonstrates how to calculate and visualize descriptive statistics:
library(tidyverse) loads the tidyverse collection of packages for data manipulation and visualization.
read_csv() imports the crop yields dataset from a CSV file.
head() displays the first few rows to inspect the data structure.
The summarize() function calculates key statistics for wheat yields:
Mean: Average yield across all observations
Median: Middle value when yields are arranged in order
StdDev: Standard deviation, measuring data dispersion
Min/Max: Minimum and maximum values in the dataset
Q1/Q3: First and third quartiles (25th and 75th percentiles)
knitr::kable() creates a formatted table of the summary statistics.
ggplot() with geom_histogram() visualizes the distribution of wheat yields.
The final section identifies and displays the top 10 countries by average wheat yield using:
group_by() to organize data by country
summarize() to calculate average yield per country
arrange(desc()) to sort in descending order
head(10) to select the top 10 entries
Results Interpretation
The summary statistics reveal several key insights about global wheat yields:
The mean wheat yield is higher than the median, suggesting a right-skewed distribution with some countries achieving exceptionally high yields.
The standard deviation indicates substantial variability in wheat productivity across different regions.
The histogram confirms this skewed distribution, with most countries clustered at lower to moderate yield levels, and fewer countries achieving very high yields.
The top 10 countries table shows which nations have the most productive wheat cultivation systems, likely due to advanced agricultural practices, favorable climate conditions, or intensive farming methods.
This analysis provides a foundation for investigating factors that contribute to high wheat yields and potential strategies for improving agricultural productivity in lower-yielding regions.
3.3.2 Frequency Tables
Frequency tables are useful for understanding the distribution of categorical variables:
Code
# Let's create a categorical variable based on wheat yield levelscrop_yields_with_categories <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%mutate(yield_category =case_when(`Wheat (tonnes per hectare)`<2~"Low",`Wheat (tonnes per hectare)`>=2&`Wheat (tonnes per hectare)`<4~"Medium",`Wheat (tonnes per hectare)`>=4~"High" ))# Frequency table for yield categoriestable(crop_yields_with_categories$yield_category)
This code block demonstrates how to create and analyze frequency tables:
mutate() with case_when() creates a new categorical variable yield_category by binning wheat yields into “Low,” “Medium,” and “High” categories.
table() produces a frequency count for each yield category.
prop.table() converts the frequency counts to proportions (relative frequencies).
A new variable decade is created by rounding down the year to the nearest decade using floor(Year / 10) * 10.
A two-way frequency table is created to examine the relationship between yield categories and decades.
prop.table(yield_decade_table, margin = 1) calculates row proportions, showing the distribution of decades within each yield category.
Results Interpretation
The frequency tables reveal important patterns in wheat yield categories:
The distribution of yield categories shows which productivity levels are most common globally.
The proportions table quantifies this distribution, indicating what percentage of observations fall into each yield category.
The two-way table between yield categories and decades allows us to track how wheat productivity has changed over time.
The row proportions reveal whether certain yield categories have become more or less common in different decades, potentially indicating technological improvements, climate effects, or changes in agricultural practices.
These temporal patterns are crucial for understanding agricultural development trends and projecting future food security scenarios.
3.3.3 Box Plots
Box plots are excellent for comparing distributions across groups:
Code
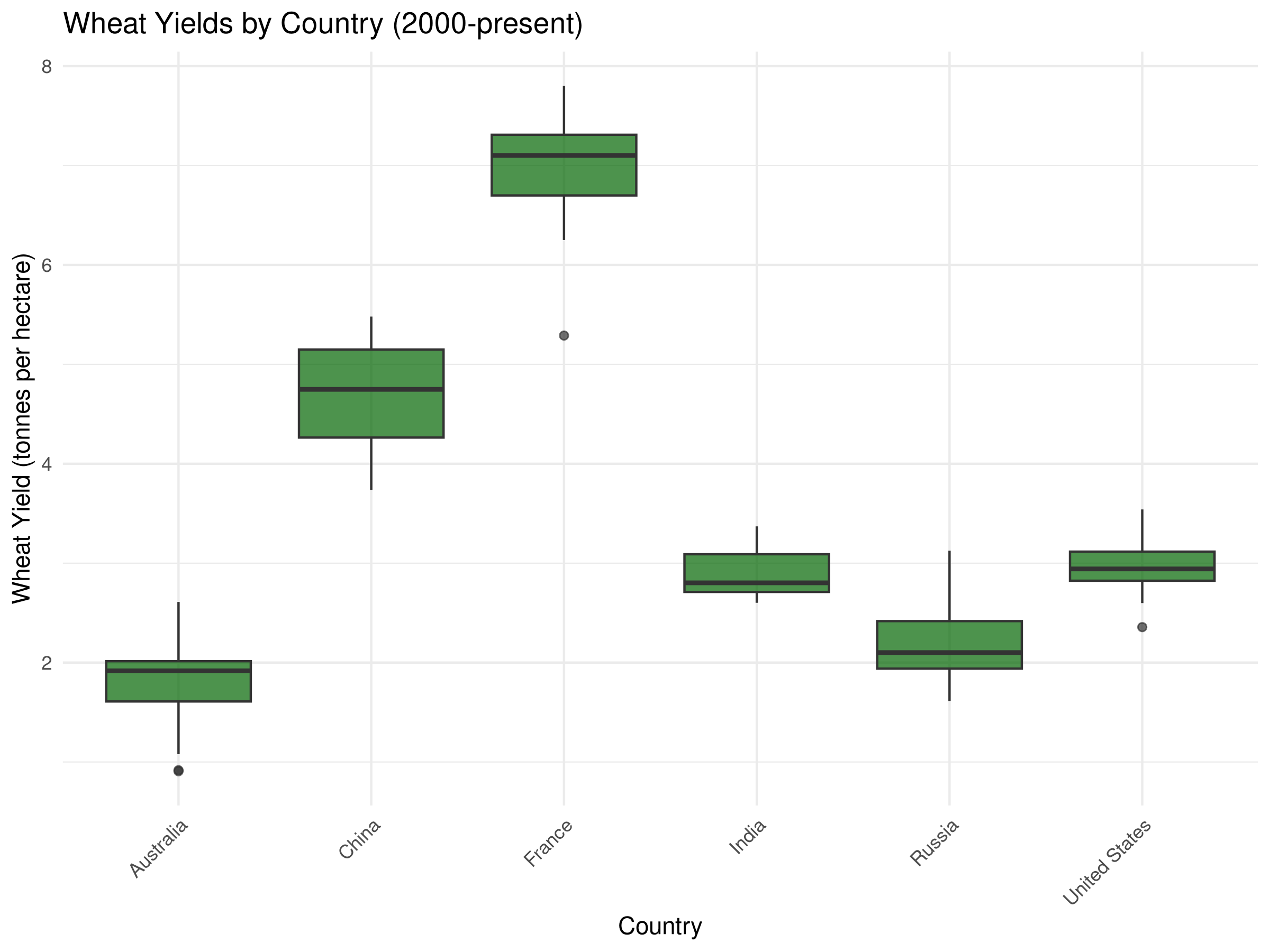
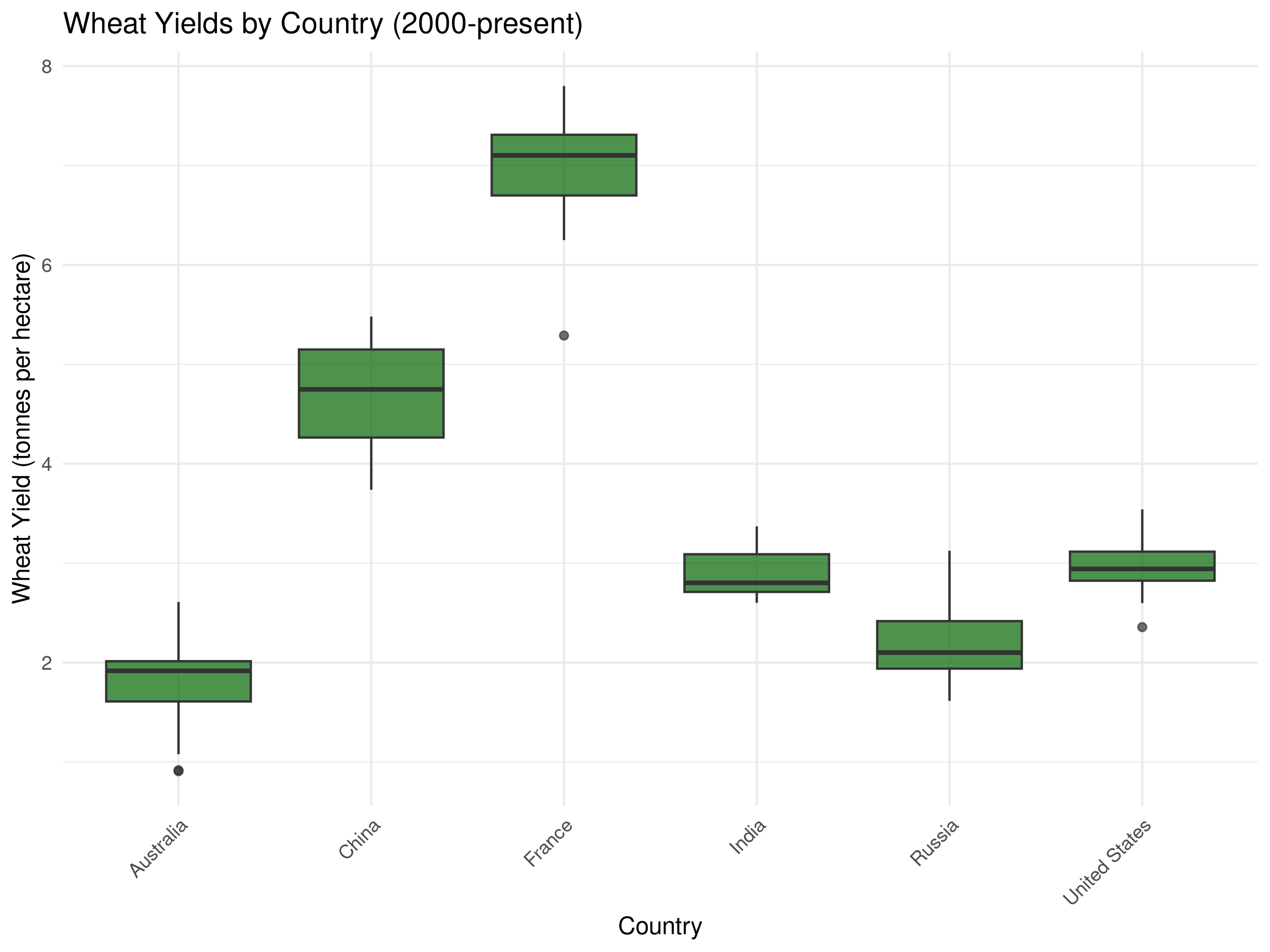
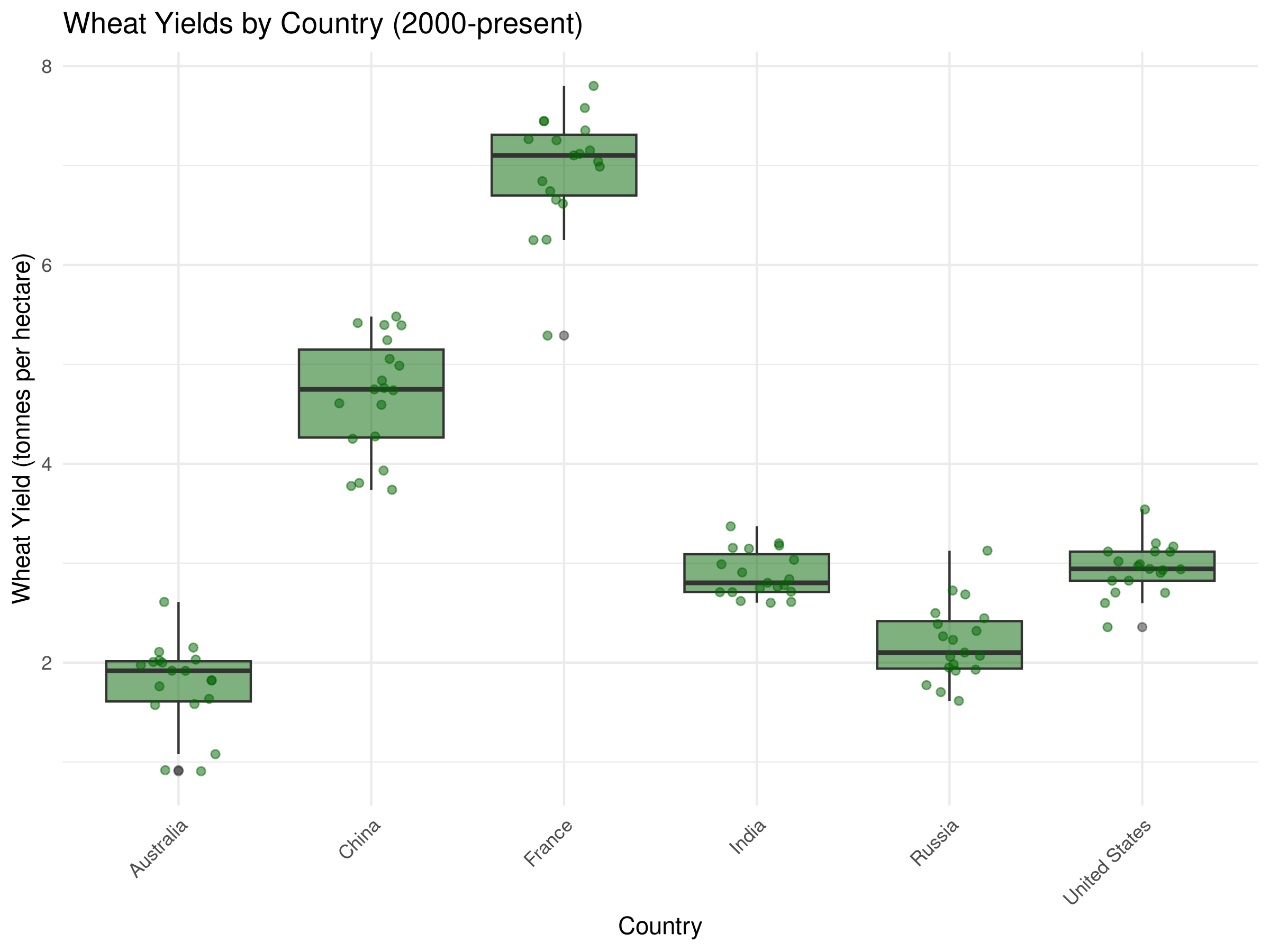
# Select a few major countries for comparisonmajor_wheat_producers <-c("United States", "China", "India", "Russia", "France", "Australia")# Filter data for these countries and recent yearsrecent_wheat_data <- crop_yields %>%filter(Entity %in% major_wheat_producers, Year >=2000,!is.na(`Wheat (tonnes per hectare)`))# Box plot of wheat yields by countryggplot(recent_wheat_data, aes(x = Entity, y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.7) +labs(title ="Wheat Yields by Country (2000-present)",x ="Country",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
Code
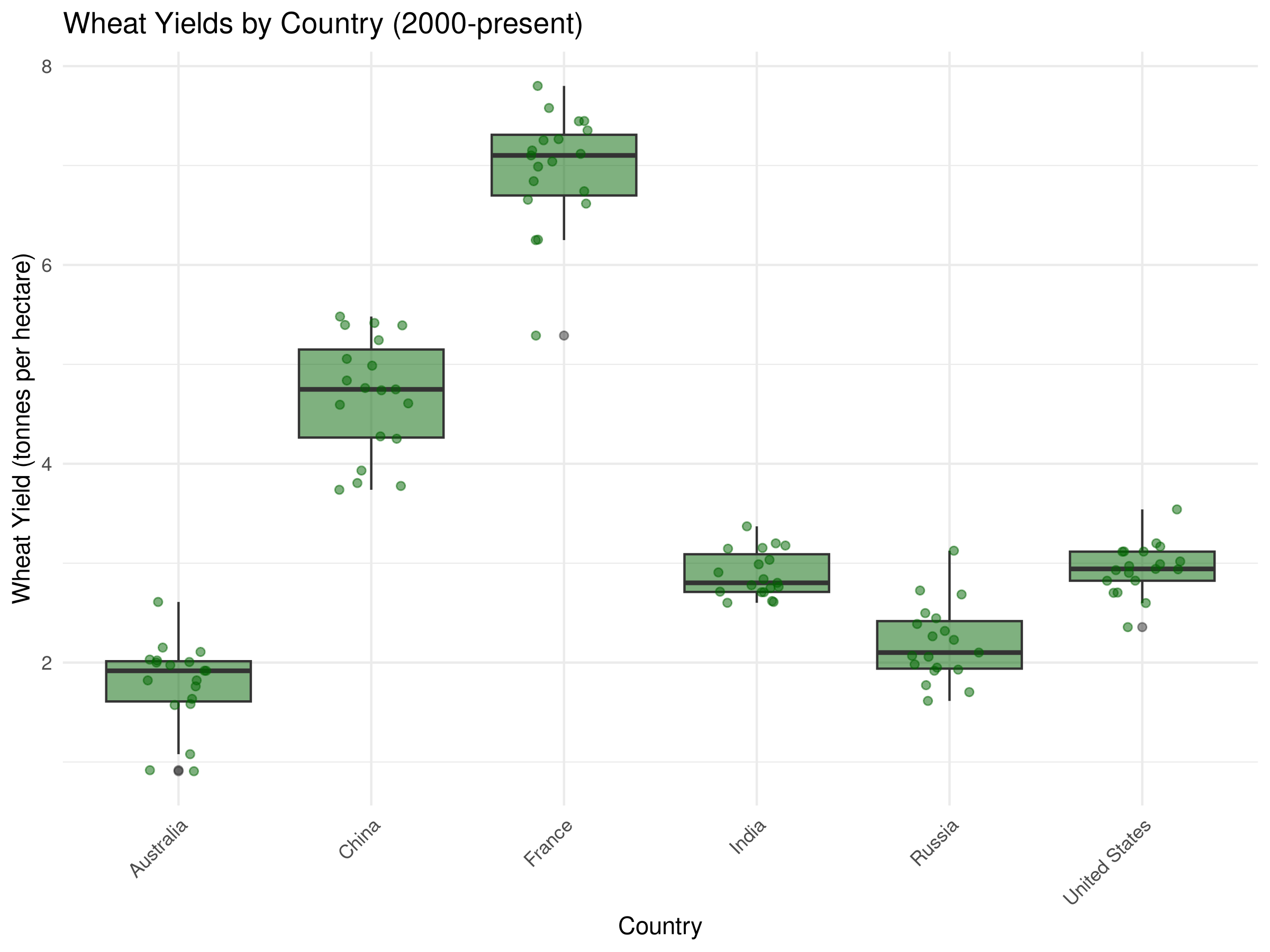
# Enhanced box plot with jittered pointsggplot(recent_wheat_data, aes(x = Entity, y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.5) +geom_jitter(width =0.2, alpha =0.5, color ="darkgreen") +labs(title ="Wheat Yields by Country (2000-present)",x ="Country",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
Code Explanation
This code demonstrates how to create and enhance box plots for comparing distributions:
First, we select major wheat-producing countries for comparison and filter for recent data (since 2000).
The basic box plot:
geom_boxplot() creates a box-and-whisker plot for each country
Each box shows the median (middle line), interquartile range (IQR, the box), and whiskers extending to 1.5 × IQR
Points beyond the whiskers represent outliers
The enhanced box plot adds:
geom_jitter() to display individual data points with slight horizontal displacement
This combination shows both the summary statistics (box plot) and the raw data distribution (points)
angle = 45, hjust = 1 rotates country labels for better readability
Results Interpretation
The box plots reveal important comparisons between major wheat-producing countries:
The median line in each box shows the typical yield for each country, allowing direct comparison of central tendency.
The height of each box (IQR) indicates the variability of yields within each country over the time period.
Whisker length reflects the range of typical yields, while outlier points show exceptional years.
Countries with higher boxes generally have more variable production, possibly due to climate fluctuations or changing agricultural practices.
The jittered points reveal the actual distribution and density of observations for each country.
These comparisons help identify which countries have the most consistent and productive wheat cultivation systems, providing insights for agricultural policy and development.
3.3.4 Bar Charts
Bar charts are useful for visualizing categorical data:
Code
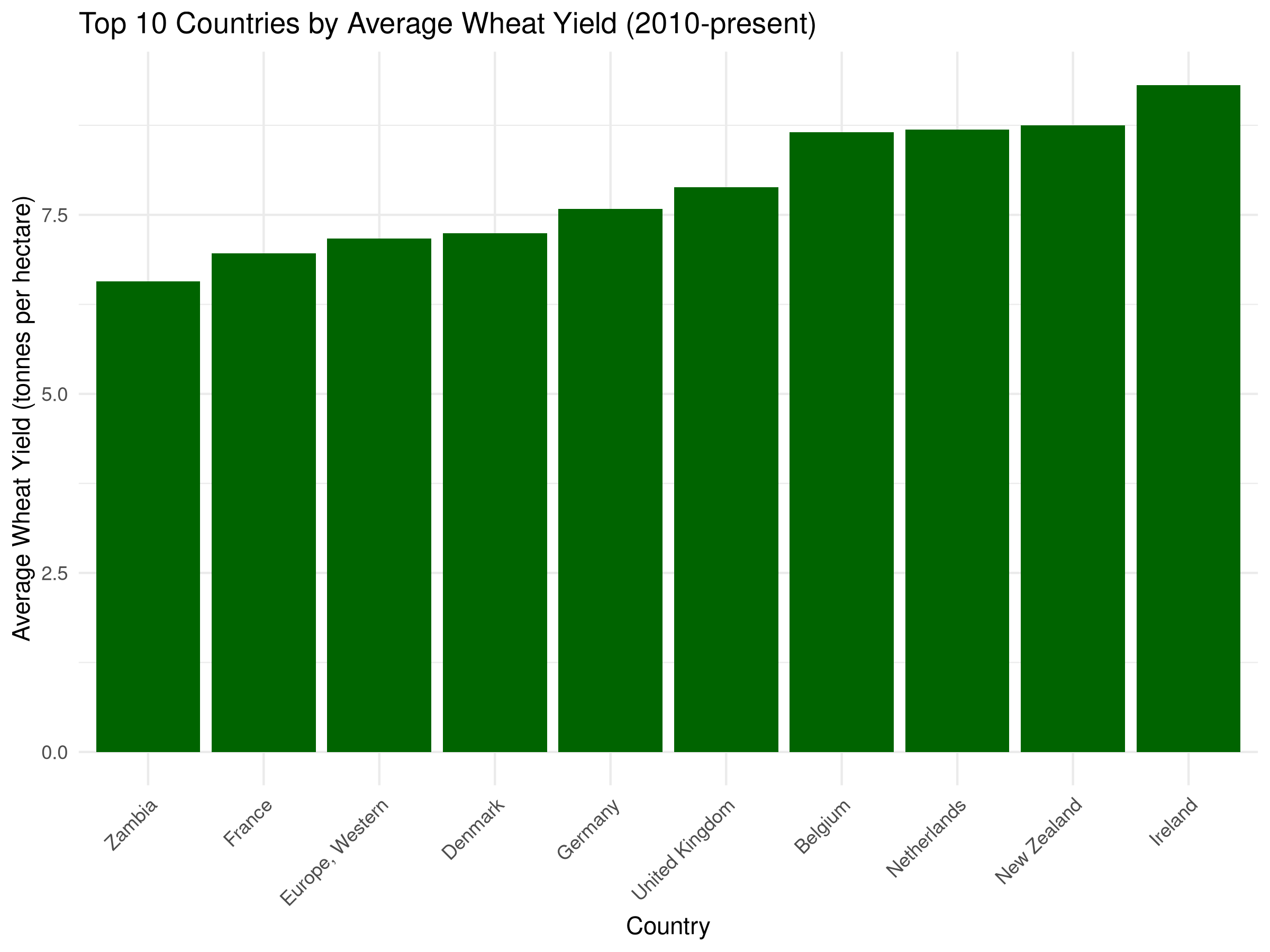
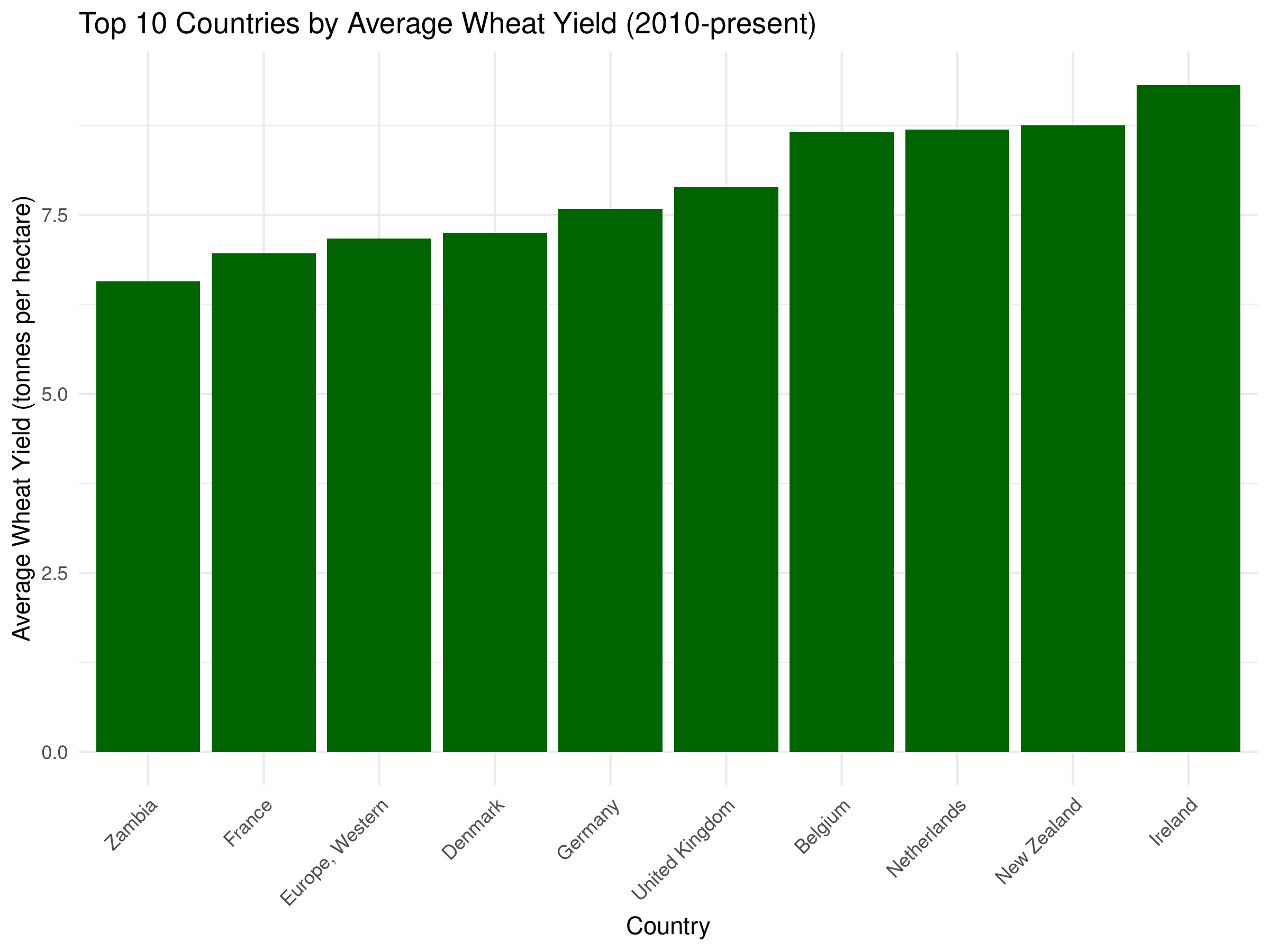
# Calculate average wheat yield by country for the last decaderecent_avg_yields <- crop_yields %>%filter(Year >=2010, !is.na(`Wheat (tonnes per hectare)`)) %>%group_by(Entity) %>%summarize(avg_wheat_yield =mean(`Wheat (tonnes per hectare)`, na.rm =TRUE)) %>%arrange(desc(avg_wheat_yield)) %>%head(10) # Top 10 countries# Bar chart of average wheat yieldsggplot(recent_avg_yields, aes(x =reorder(Entity, avg_wheat_yield), y = avg_wheat_yield)) +geom_bar(stat ="identity", fill ="darkgreen") +labs(title ="Top 10 Countries by Average Wheat Yield (2010-present)",x ="Country",y ="Average Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
Code Explanation
This code demonstrates how to create a bar chart for visualizing categorical data:
First, we calculate the average wheat yield by country for the last decade (2010-present).
We then select the top 10 countries by average yield.
The bar chart:
geom_bar(stat = "identity") creates a bar for each country, with height proportional to average yield
reorder(Entity, avg_wheat_yield) sorts the countries by average yield in descending order
fill = "darkgreen" sets the bar color
theme(axis.text.x = element_text(angle = 45, hjust = 1)) rotates country labels for better readability
Results Interpretation
The bar chart reveals the top 10 countries by average wheat yield:
The height of each bar represents the average yield for each country.
The countries are sorted in descending order by average yield, making it easy to identify the most productive nations.
This visualization helps identify which countries have the most efficient wheat cultivation systems, providing insights for agricultural policy and development.
The bar chart can also be used to compare the average yields of different countries, helping to identify potential areas for improvement.
3.4 Visualizing Distributions
3.4.1 Histograms and Density Plots
Histograms and density plots help visualize the distribution of continuous variables:
Code
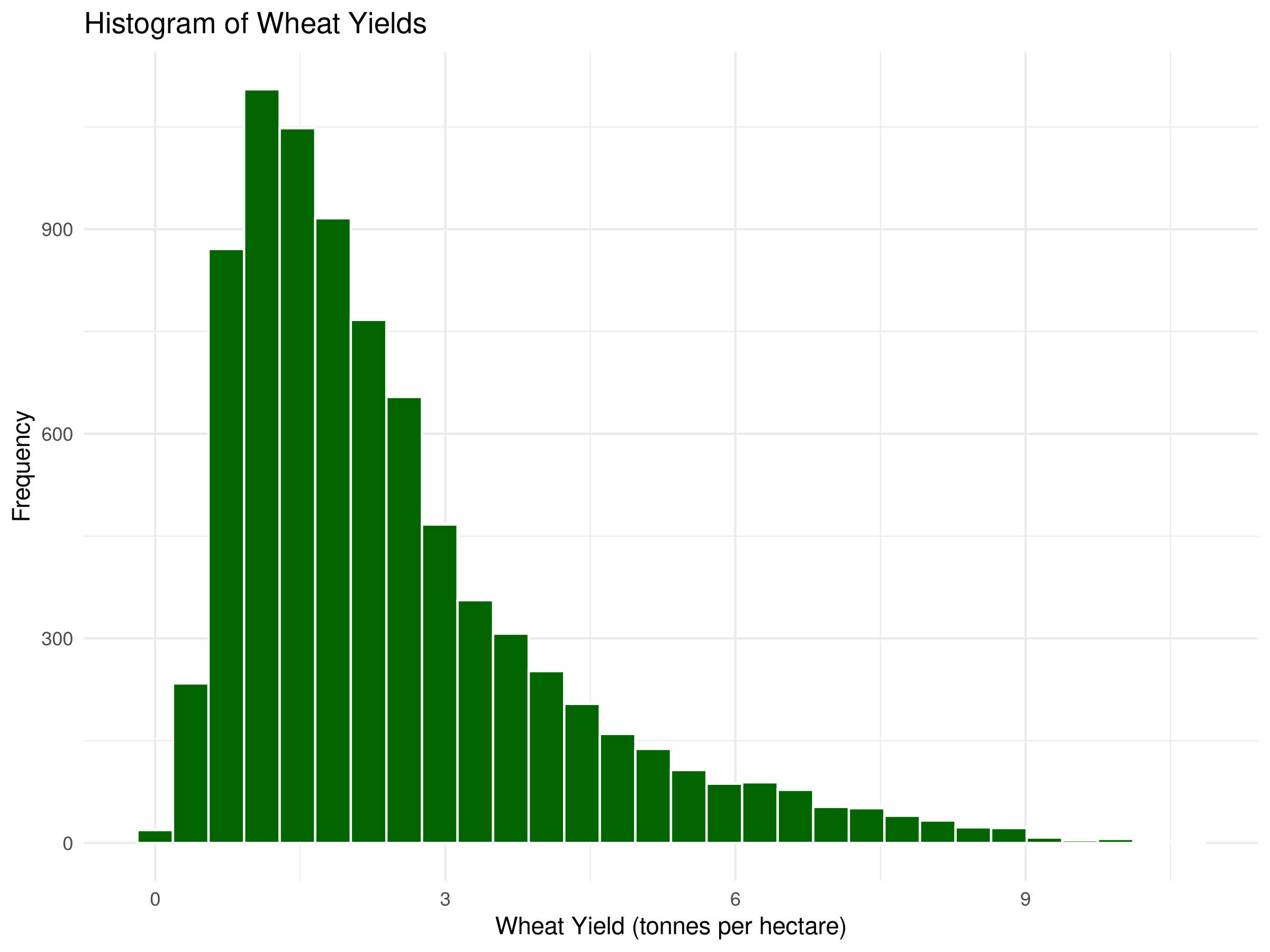
# Histogram of wheat yieldsggplot(crop_yields, aes(x =`Wheat (tonnes per hectare)`)) +geom_histogram(bins =30, fill ="darkgreen", color ="white", na.rm =TRUE) +labs(title ="Histogram of Wheat Yields",x ="Wheat Yield (tonnes per hectare)",y ="Frequency") +theme_minimal()
Code
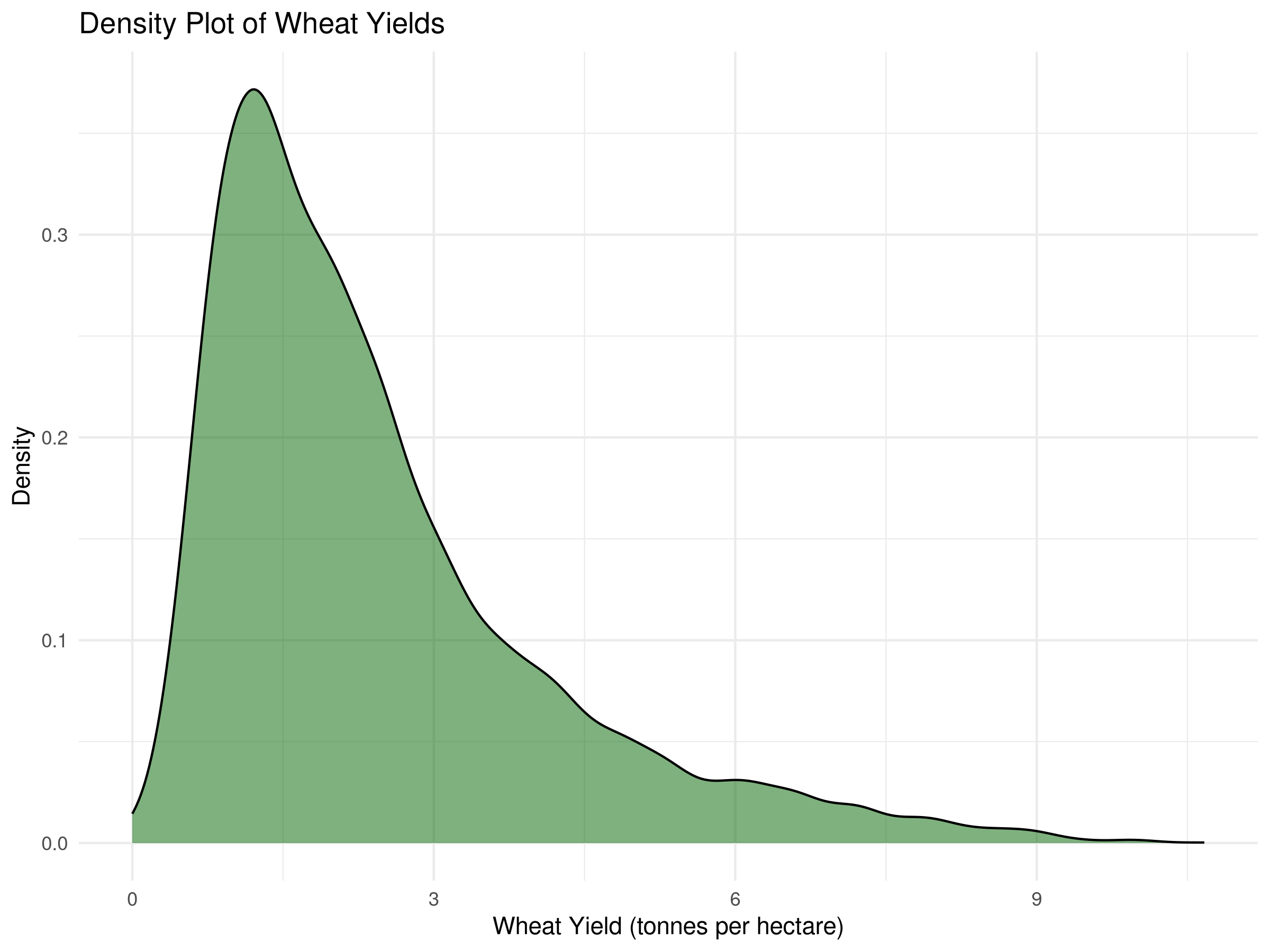
# Density plotggplot(crop_yields, aes(x =`Wheat (tonnes per hectare)`)) +geom_density(fill ="darkgreen", alpha =0.5, na.rm =TRUE) +labs(title ="Density Plot of Wheat Yields",x ="Wheat Yield (tonnes per hectare)",y ="Density") +theme_minimal()
Code
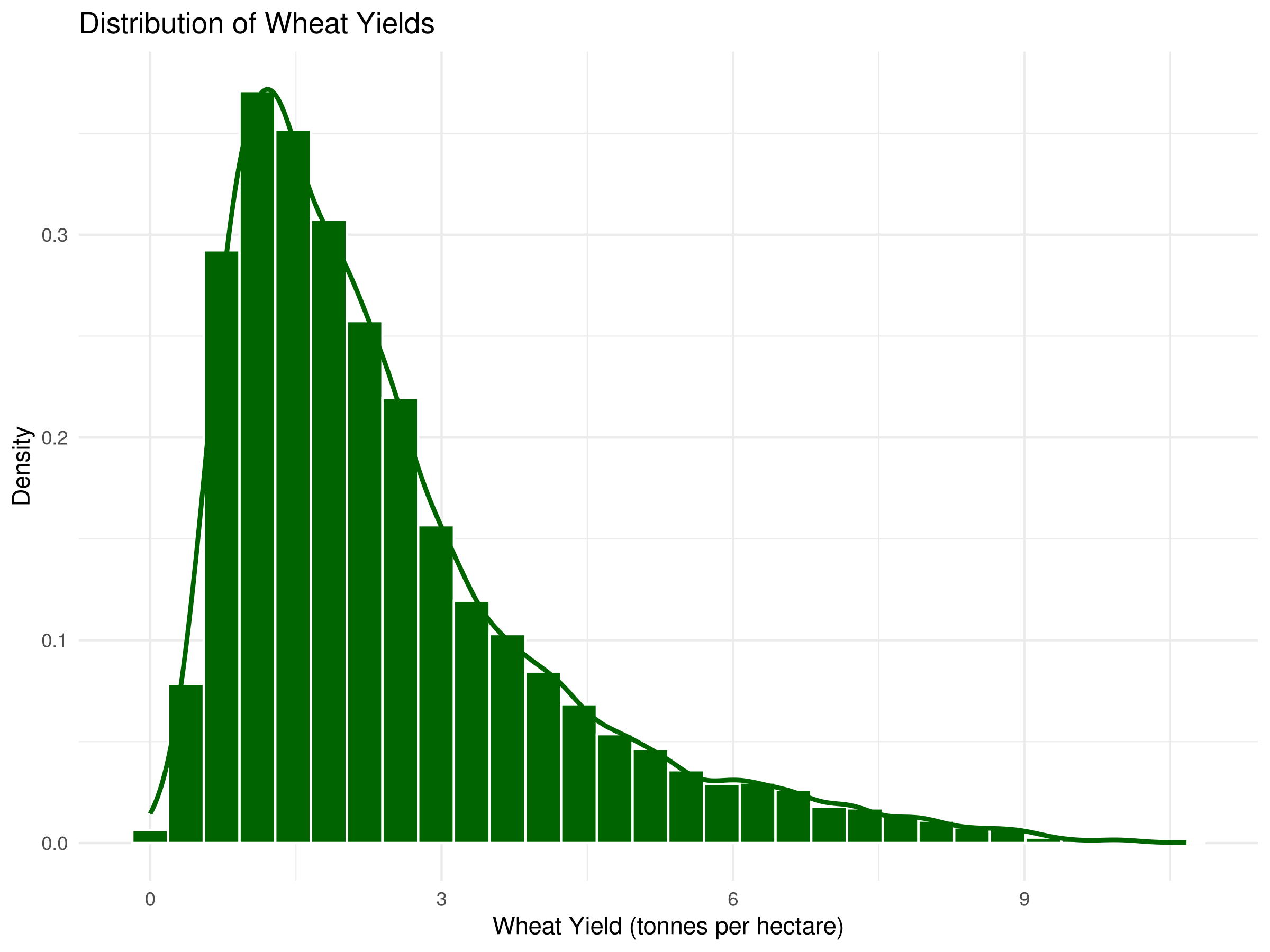
# Histogram with density overlayggplot(crop_yields, aes(x =`Wheat (tonnes per hectare)`)) +geom_histogram(aes(y = ..density..), bins =30, fill ="darkgreen", color ="white", na.rm =TRUE) +geom_density(color ="darkgreen", linewidth =1, na.rm =TRUE) +labs(title ="Distribution of Wheat Yields",x ="Wheat Yield (tonnes per hectare)",y ="Density") +theme_minimal()
Code Explanation
This code demonstrates three approaches to visualizing distributions:
Histogram:
geom_histogram() divides the data into bins and counts observations in each bin
bins = 30 specifies the number of divisions
na.rm = TRUE removes missing values from the visualization
Density Plot:
geom_density() creates a smoothed representation of the distribution
fill and alpha control the appearance and transparency
Density plots show the probability density function of the data
Combined Visualization:
The histogram is converted to density scale with aes(y = ..density..)
geom_density() overlays a smoothed curve on the histogram
This combination shows both the raw data structure and the smoothed distribution
Results Interpretation
These distribution visualizations reveal key patterns in wheat yields:
The histogram shows the frequency of observations at different yield levels, highlighting where most countries cluster.
The density plot smooths the distribution, making it easier to identify the central tendency and spread.
The combined plot allows us to see both the actual data distribution (histogram) and the underlying probability density (curve).
The right-skewed shape indicates that while most countries have moderate yields, a few achieve exceptionally high productivity.
Multiple peaks (if present) might suggest distinct groups of countries with different agricultural technologies or growing conditions.
These visualizations help identify outliers and understand the overall pattern of global wheat production efficiency.
3.4.2 Box Plots
Box plots are excellent for comparing distributions across groups:
Code
# Select a few major countries for comparisonmajor_wheat_producers <-c("United States", "China", "India", "Russia", "France", "Australia")# Filter data for these countries and recent yearsrecent_wheat_data <- crop_yields %>%filter(Entity %in% major_wheat_producers, Year >=2000,!is.na(`Wheat (tonnes per hectare)`))# Box plot of wheat yields by countryggplot(recent_wheat_data, aes(x = Entity, y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.7) +labs(title ="Wheat Yields by Country (2000-present)",x ="Country",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
Code
# Enhanced box plot with jittered pointsggplot(recent_wheat_data, aes(x = Entity, y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.5) +geom_jitter(width =0.2, alpha =0.5, color ="darkgreen") +labs(title ="Wheat Yields by Country (2000-present)",x ="Country",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
Code Explanation
This code demonstrates how to create and enhance box plots for comparing distributions:
First, we select major wheat-producing countries for comparison and filter for recent data (since 2000).
The basic box plot:
geom_boxplot() creates a box-and-whisker plot for each country
Each box shows the median (middle line), interquartile range (IQR, the box), and whiskers extending to 1.5 × IQR
Points beyond the whiskers represent outliers
The enhanced box plot adds:
geom_jitter() to display individual data points with slight horizontal displacement
This combination shows both the summary statistics (box plot) and the raw data distribution (points)
angle = 45, hjust = 1 rotates country labels for better readability
Results Interpretation
The box plots reveal important comparisons between major wheat-producing countries:
The median line in each box shows the typical yield for each country, allowing direct comparison of central tendency.
The height of each box (IQR) indicates the variability of yields within each country over the time period.
Whisker length reflects the range of typical yields, while outlier points show exceptional years.
Countries with higher boxes generally have more variable production, possibly due to climate fluctuations or changing agricultural practices.
The jittered points reveal the actual distribution and density of observations for each country.
These comparisons help identify which countries have the most consistent and productive wheat cultivation systems, providing insights for agricultural policy and development.
3.4.3 Bar Charts
Bar charts are useful for visualizing categorical data:
Code
# Calculate average wheat yield by country for the last decaderecent_avg_yields <- crop_yields %>%filter(Year >=2010, !is.na(`Wheat (tonnes per hectare)`)) %>%group_by(Entity) %>%summarize(avg_wheat_yield =mean(`Wheat (tonnes per hectare)`, na.rm =TRUE)) %>%arrange(desc(avg_wheat_yield)) %>%head(10) # Top 10 countries# Bar chart of average wheat yieldsggplot(recent_avg_yields, aes(x =reorder(Entity, avg_wheat_yield), y = avg_wheat_yield)) +geom_bar(stat ="identity", fill ="darkgreen") +labs(title ="Top 10 Countries by Average Wheat Yield (2010-present)",x ="Country",y ="Average Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
Code Explanation
This code demonstrates how to create a bar chart for visualizing categorical data:
First, we calculate the average wheat yield by country for the last decade (2010-present).
We then select the top 10 countries by average yield.
The bar chart:
geom_bar(stat = "identity") creates a bar for each country, with height proportional to average yield
reorder(Entity, avg_wheat_yield) sorts the countries by average yield in descending order
fill = "darkgreen" sets the bar color
theme(axis.text.x = element_text(angle = 45, hjust = 1)) rotates country labels for better readability
Results Interpretation
The bar chart reveals the top 10 countries by average wheat yield:
The height of each bar represents the average yield for each country.
The countries are sorted in descending order by average yield, making it easy to identify the most productive nations.
This visualization helps identify which countries have the most efficient wheat cultivation systems, providing insights for agricultural policy and development.
The bar chart can also be used to compare the average yields of different countries, helping to identify potential areas for improvement.
3.5 Exploring Relationships
3.5.1 Scatter Plots
Scatter plots help visualize relationships between two continuous variables:
Code
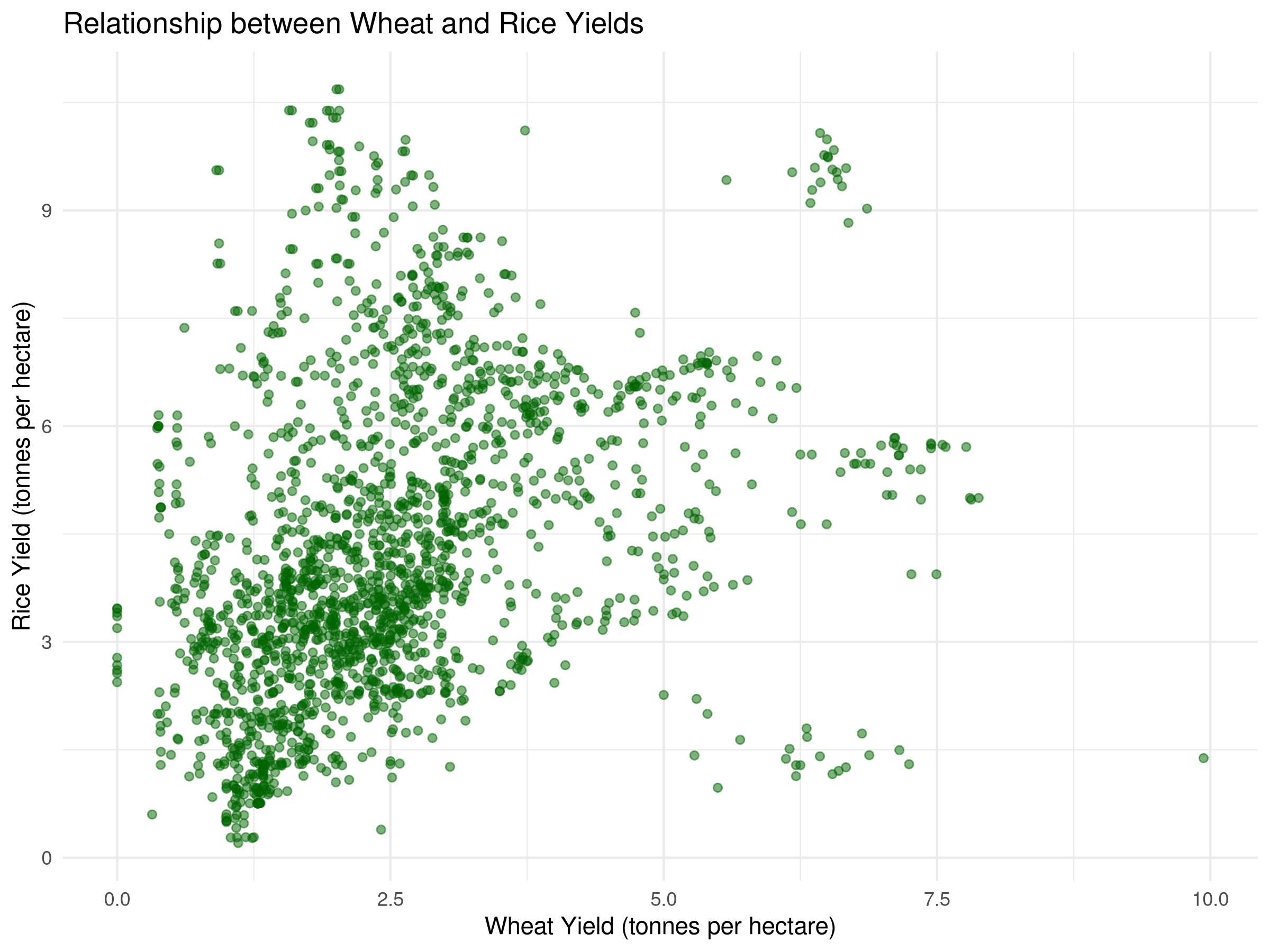
# Let's compare wheat and rice yieldscrop_yields_filtered <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`), !is.na(`Rice (tonnes per hectare)`)) %>%filter(Year >=2000)# Basic scatter plotggplot(crop_yields_filtered, aes(x =`Wheat (tonnes per hectare)`, y =`Rice (tonnes per hectare)`)) +geom_point(alpha =0.5, color ="darkgreen") +labs(title ="Relationship between Wheat and Rice Yields",x ="Wheat Yield (tonnes per hectare)",y ="Rice Yield (tonnes per hectare)") +theme_minimal()
Code
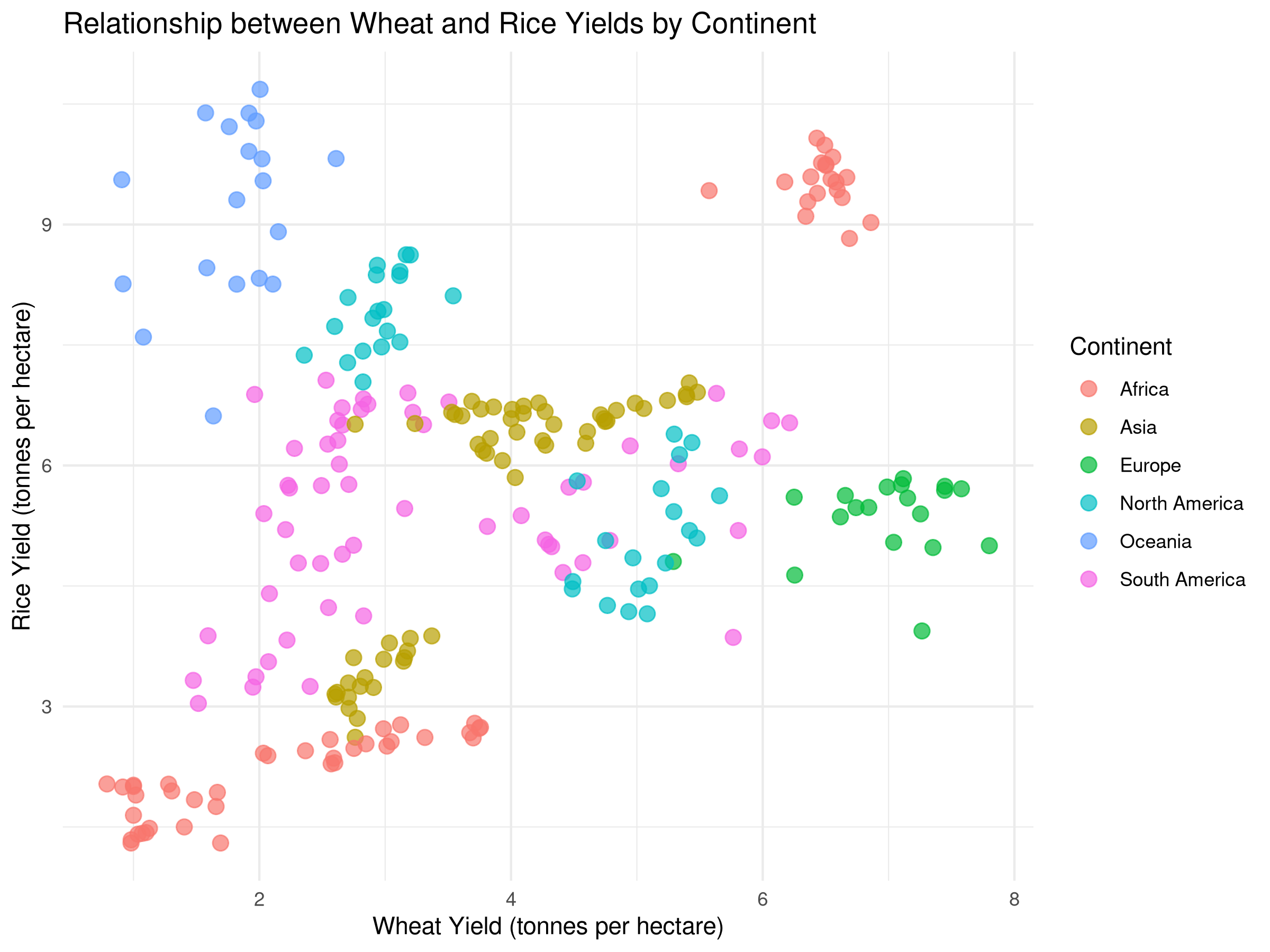
# Scatter plot with color by continent (we'll need to add continent information)# For demonstration, let's create a simple mapping for a few countriescontinent_mapping <-tibble(Entity =c("United States", "Canada", "Mexico","China", "India", "Japan","Germany", "France", "United Kingdom","Brazil", "Argentina", "Chile","Egypt", "Nigeria", "South Africa","Australia", "New Zealand"),Continent =c(rep("North America", 3),rep("Asia", 3),rep("Europe", 3),rep("South America", 3),rep("Africa", 3),rep("Oceania", 2)))# Join with our datasetcrop_yields_with_continent <- crop_yields_filtered %>%inner_join(continent_mapping, by ="Entity")# Scatter plot with color by continentggplot(crop_yields_with_continent, aes(x =`Wheat (tonnes per hectare)`, y =`Rice (tonnes per hectare)`, color = Continent)) +geom_point(size =3, alpha =0.7) +labs(title ="Relationship between Wheat and Rice Yields by Continent",x ="Wheat Yield (tonnes per hectare)",y ="Rice Yield (tonnes per hectare)") +theme_minimal()
Code Explanation
This code demonstrates how to create scatter plots for exploring relationships:
First, we filter the data to include only observations with non-missing values for wheat and rice yields, and only consider recent data (since 2000).
The basic scatter plot:
geom_point() creates a scatter plot of wheat yields vs. rice yields
alpha = 0.5 sets the transparency of the points
color = "darkgreen" sets the color of the points
The scatter plot with color by continent:
We create a simple mapping of countries to continents using tibble().
We join this mapping with our dataset using inner_join().
We create a scatter plot with color by continent using geom_point(aes(color = Continent)).
Results Interpretation
The scatter plots reveal the relationship between wheat and rice yields:
The basic scatter plot shows the overall relationship between wheat and rice yields.
The scatter plot with color by continent reveals how the relationship varies across different continents.
This visualization helps identify patterns and correlations between wheat and rice yields, providing insights for agricultural policy and development.
The scatter plot can also be used to identify outliers and anomalies in the data.
3.5.2 Correlation Analysis
Correlation analysis quantifies the strength and direction of relationships between variables:
Code
# Select numeric columns for correlation analysiscrop_numeric <- crop_yields %>%select(`Wheat (tonnes per hectare)`, `Rice (tonnes per hectare)`, `Maize (tonnes per hectare)`, `Soybeans (tonnes per hectare)`, `Potatoes (tonnes per hectare)`, `Beans (tonnes per hectare)`) %>%na.omit()# Correlation matrixcor_matrix <-cor(crop_numeric)round(cor_matrix, 2)
Wheat (tonnes per hectare)
Wheat (tonnes per hectare) 1.00
Rice (tonnes per hectare) 0.43
Maize (tonnes per hectare) 0.57
Soybeans (tonnes per hectare) 0.47
Potatoes (tonnes per hectare) 0.57
Beans (tonnes per hectare) 0.44
Rice (tonnes per hectare)
Wheat (tonnes per hectare) 0.43
Rice (tonnes per hectare) 1.00
Maize (tonnes per hectare) 0.73
Soybeans (tonnes per hectare) 0.58
Potatoes (tonnes per hectare) 0.67
Beans (tonnes per hectare) 0.46
Maize (tonnes per hectare)
Wheat (tonnes per hectare) 0.57
Rice (tonnes per hectare) 0.73
Maize (tonnes per hectare) 1.00
Soybeans (tonnes per hectare) 0.65
Potatoes (tonnes per hectare) 0.74
Beans (tonnes per hectare) 0.63
Soybeans (tonnes per hectare)
Wheat (tonnes per hectare) 0.47
Rice (tonnes per hectare) 0.58
Maize (tonnes per hectare) 0.65
Soybeans (tonnes per hectare) 1.00
Potatoes (tonnes per hectare) 0.59
Beans (tonnes per hectare) 0.41
Potatoes (tonnes per hectare)
Wheat (tonnes per hectare) 0.57
Rice (tonnes per hectare) 0.67
Maize (tonnes per hectare) 0.74
Soybeans (tonnes per hectare) 0.59
Potatoes (tonnes per hectare) 1.00
Beans (tonnes per hectare) 0.46
Beans (tonnes per hectare)
Wheat (tonnes per hectare) 0.44
Rice (tonnes per hectare) 0.46
Maize (tonnes per hectare) 0.63
Soybeans (tonnes per hectare) 0.41
Potatoes (tonnes per hectare) 0.46
Beans (tonnes per hectare) 1.00
Code
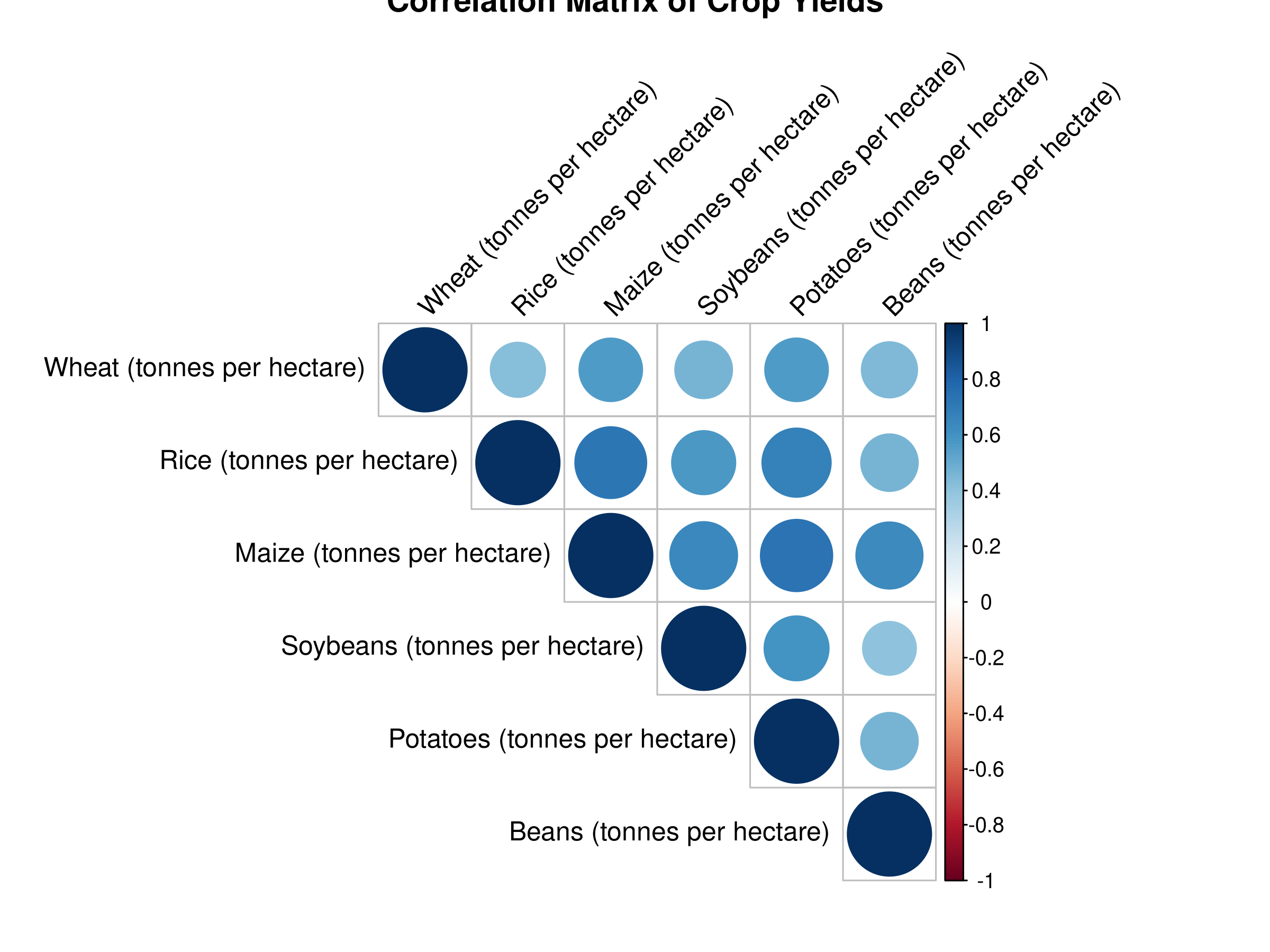
# Visualize correlation matrixlibrary(corrplot)corrplot(cor_matrix, method ="circle", type ="upper",tl.col ="black", tl.srt =45,title ="Correlation Matrix of Crop Yields")
Code Explanation
This code demonstrates how to perform correlation analysis:
First, we select the numeric columns of interest for correlation analysis.
We remove any missing values using na.omit().
We calculate the correlation matrix using cor().
We round the correlation matrix to 2 decimal places using round().
We visualize the correlation matrix using corrplot().
Results Interpretation
The correlation matrix reveals the strength and direction of relationships between variables:
The correlation matrix shows the correlation coefficients between each pair of variables.
The correlation coefficients range from -1 (perfect negative correlation) to 1 (perfect positive correlation).
This visualization helps identify strong correlations between variables, providing insights for agricultural policy and development.
The correlation matrix can also be used to identify potential multicollinearity issues in regression analysis.
3.5.3 Pair Plots
Pair plots provide a comprehensive view of relationships between multiple variables:
Code
# Basic pair plotpairs(crop_numeric, pch =19, col ="darkgreen")
Code
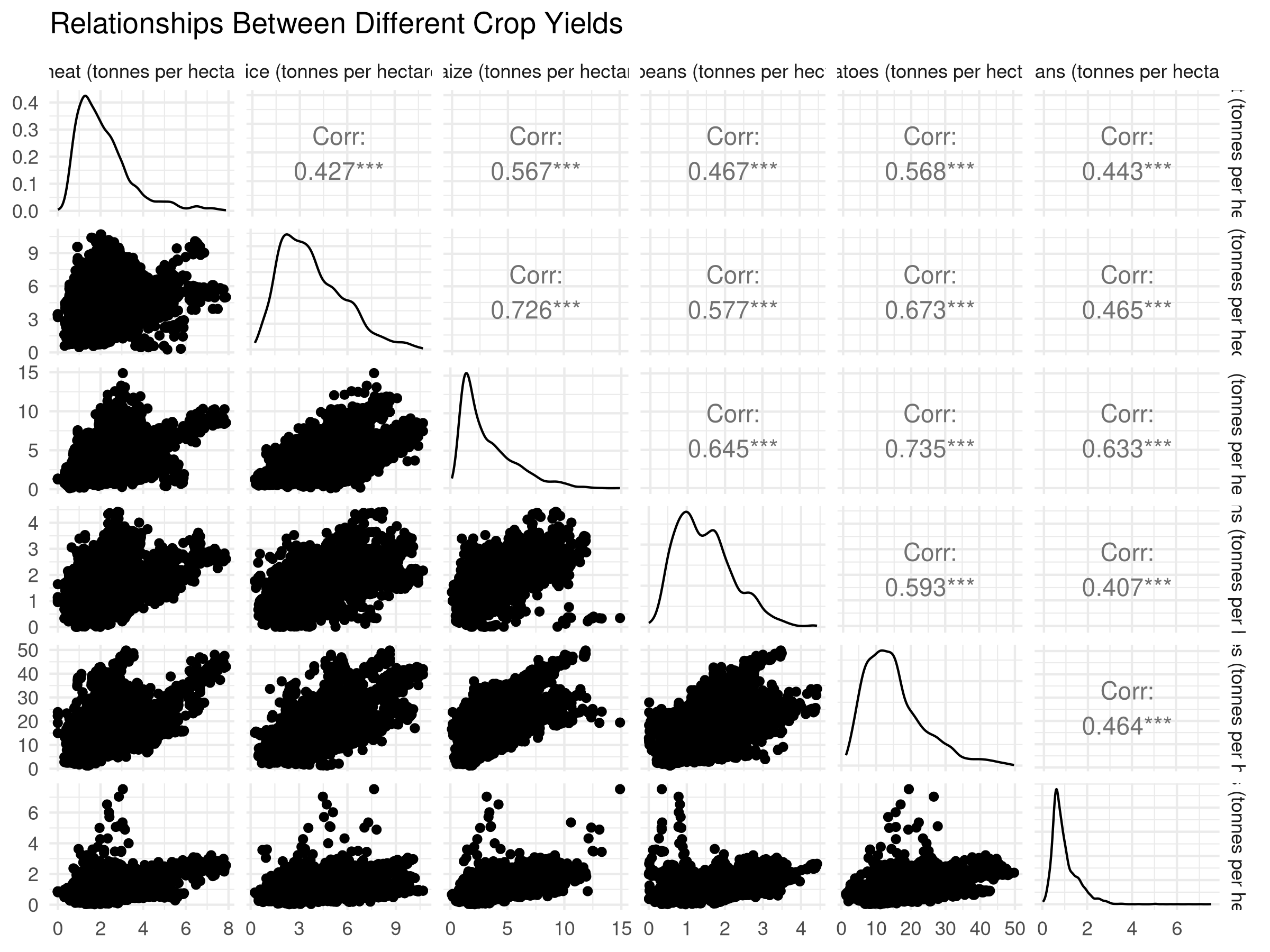
# Enhanced pair plot with GGallylibrary(GGally)ggpairs(crop_numeric) +theme_minimal() +labs(title ="Relationships Between Different Crop Yields")
Code Explanation
This code demonstrates how to create pair plots:
First, we create a basic pair plot using pairs().
We then create an enhanced pair plot using ggpairs() from the GGally package.
The enhanced pair plot includes histograms, scatter plots, and correlation coefficients for each pair of variables.
Results Interpretation
The pair plots reveal the relationships between multiple variables:
The pair plots show the relationships between each pair of variables.
The histograms and scatter plots provide a visual representation of the relationships.
The correlation coefficients provide a quantitative measure of the strength and direction of the relationships.
This visualization helps identify patterns and correlations between multiple variables, providing insights for agricultural policy and development.
3.6 Identifying Outliers and Anomalies
3.6.1 Box Plots for Outlier Detection
Box plots can help identify potential outliers:
Code
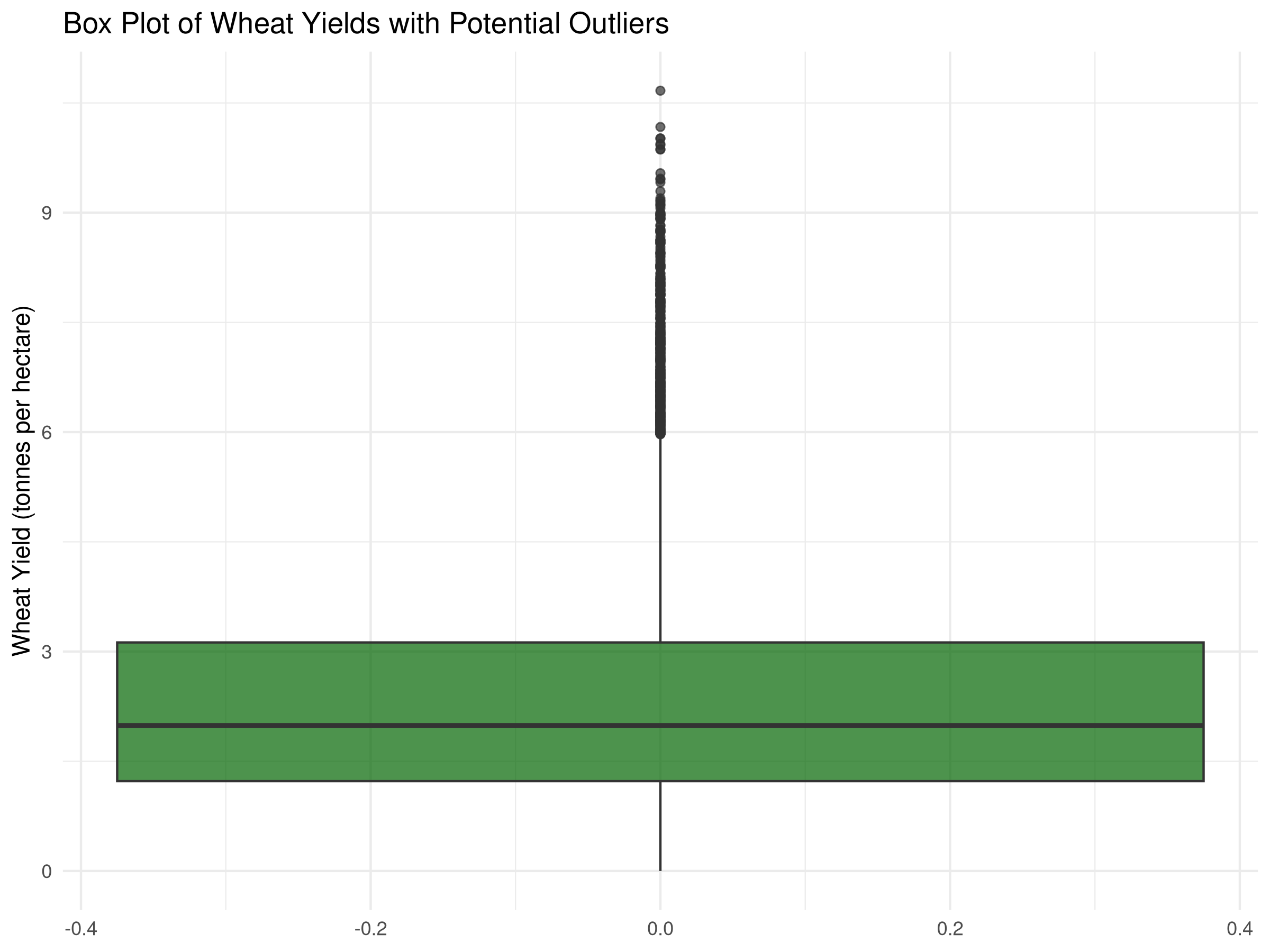
# Box plot to identify outliers in wheat yieldggplot(crop_yields, aes(y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.7, na.rm =TRUE) +labs(title ="Box Plot of Wheat Yields with Potential Outliers",y ="Wheat Yield (tonnes per hectare)") +theme_minimal()
Code
# Identify potential outlierswheat_outliers <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%mutate(q1 =quantile(`Wheat (tonnes per hectare)`, 0.25),q3 =quantile(`Wheat (tonnes per hectare)`, 0.75),iqr = q3 - q1,lower_bound = q1 -1.5* iqr,upper_bound = q3 +1.5* iqr,is_outlier =`Wheat (tonnes per hectare)`< lower_bound |`Wheat (tonnes per hectare)`> upper_bound ) %>%filter(is_outlier) %>%select(Entity, Year, `Wheat (tonnes per hectare)`)# Display the outliershead(wheat_outliers, 10)
This code demonstrates how to use z-scores for outlier detection:
First, we calculate the mean and standard deviation of wheat yields using mean() and sd(), respectively.
We then calculate the z-scores for each observation using (x - mean) / sd.
We identify observations with absolute z-scores greater than 3 as extreme values.
Results Interpretation
The z-scores reveal extreme values:
The z-scores show the number of standard deviations from the mean for each observation.
The extreme values are identified by their absolute z-scores greater than 3.
This visualization helps identify potential outliers or anomalies in the data, providing insights for data cleaning and quality control.
3.7 Time Series Exploration
Agricultural data often contains important temporal patterns:
Code
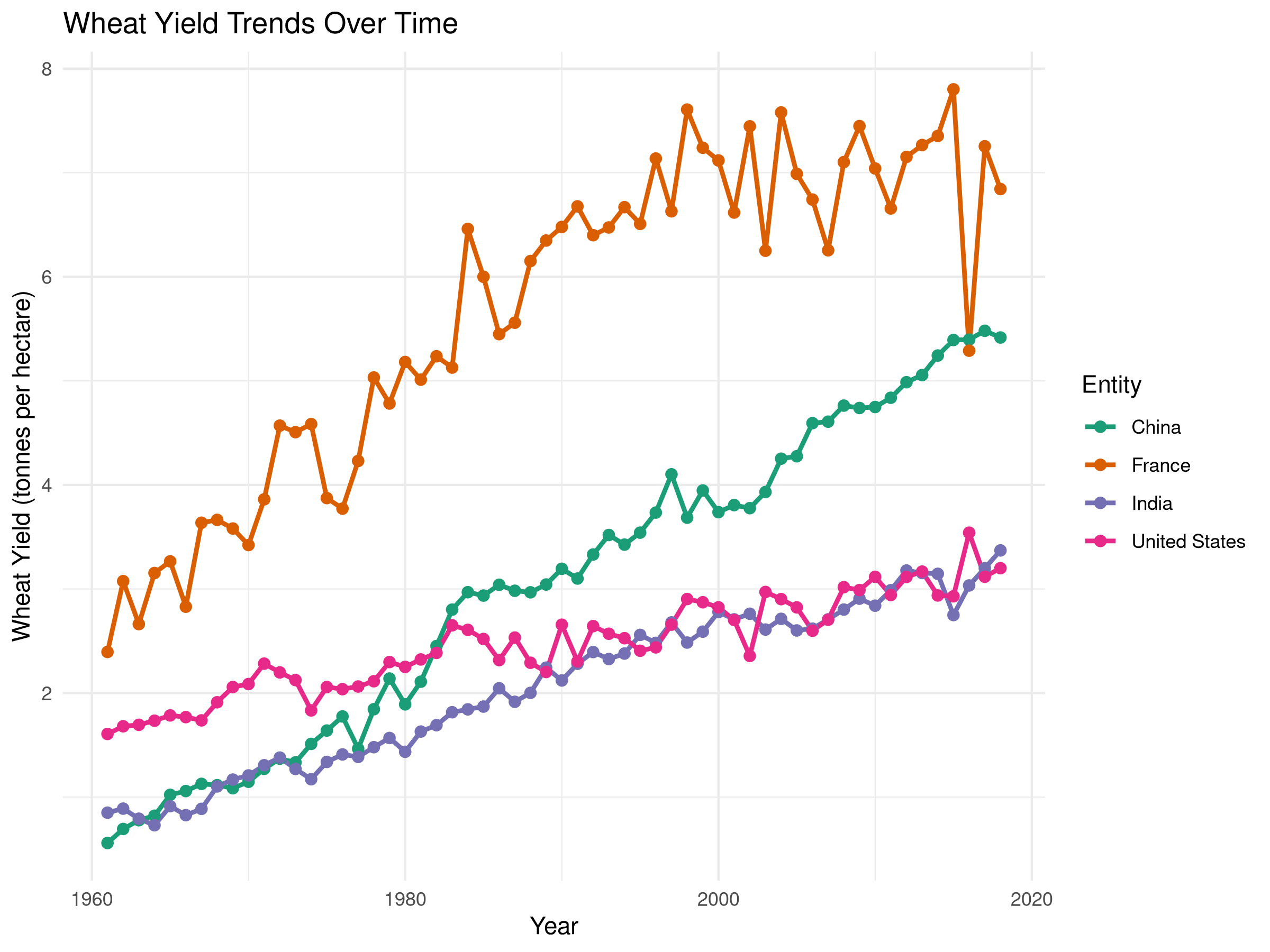
# Select a few countries for time series analysiscountries_for_ts <-c("United States", "China", "India", "France")# Filter data for these countrieswheat_ts_data <- crop_yields %>%filter(Entity %in% countries_for_ts, !is.na(`Wheat (tonnes per hectare)`)) %>%filter(Year >=1960)# Time series plotggplot(wheat_ts_data, aes(x = Year, y =`Wheat (tonnes per hectare)`, color = Entity)) +geom_line(linewidth =1) +geom_point(size =2) +labs(title ="Wheat Yield Trends Over Time",x ="Year",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +scale_color_brewer(palette ="Dark2")
Code Explanation
This code demonstrates how to create a time series plot:
First, we select a few countries for time series analysis.
We filter the data for these countries and non-missing wheat yields.
We create a time series plot using geom_line() and geom_point().
We add a title, x-axis label, and y-axis label using labs().
Results Interpretation
The time series plot reveals temporal patterns:
The time series plot shows the trends in wheat yields over time for each country.
The plot reveals patterns such as increasing or decreasing trends, seasonality, or anomalies.
This visualization helps identify temporal patterns and correlations in the data, providing insights for agricultural policy and development.
3.8 Missing Data Analysis
Understanding patterns of missing data is crucial:
Code
# Check for missing values in each columncolSums(is.na(crop_yields))
Entity Code
0 1919
Year Wheat (tonnes per hectare)
0 4974
Rice (tonnes per hectare) Maize (tonnes per hectare)
4604 2301
Soybeans (tonnes per hectare) Potatoes (tonnes per hectare)
7114 3059
Beans (tonnes per hectare) Peas (tonnes per hectare)
5066 6840
Cassava (tonnes per hectare) Barley (tonnes per hectare)
5887 6342
Cocoa beans (tonnes per hectare) Bananas (tonnes per hectare)
8466 4166
Code
# Visualize missing data patternsif(requireNamespace("naniar", quietly =TRUE)) {library(naniar)# Create a visualization of missing datagg_miss_var(crop_yields)# Create a matrix showing missing data patternsvis_miss(crop_yields[, c("Entity", "Year", "Wheat (tonnes per hectare)", "Rice (tonnes per hectare)", "Maize (tonnes per hectare)")])} else {message("The 'naniar' package is not installed. Install it with install.packages('naniar') to visualize missing data patterns.")# Alternative: simple summary of missing data missing_summary <-sapply(crop_yields, function(x) sum(is.na(x))) missing_df <-data.frame(Variable =names(missing_summary),Missing_Count = missing_summary,Missing_Percent =round(missing_summary /nrow(crop_yields) *100, 2) )# Display the summary missing_df <- missing_df[order(-missing_df$Missing_Count), ]head(missing_df, 10)}
Variable Missing_Count
Cocoa beans (tonnes per hectare) Cocoa beans (tonnes per hectare) 8466
Soybeans (tonnes per hectare) Soybeans (tonnes per hectare) 7114
Peas (tonnes per hectare) Peas (tonnes per hectare) 6840
Barley (tonnes per hectare) Barley (tonnes per hectare) 6342
Cassava (tonnes per hectare) Cassava (tonnes per hectare) 5887
Beans (tonnes per hectare) Beans (tonnes per hectare) 5066
Wheat (tonnes per hectare) Wheat (tonnes per hectare) 4974
Rice (tonnes per hectare) Rice (tonnes per hectare) 4604
Bananas (tonnes per hectare) Bananas (tonnes per hectare) 4166
Potatoes (tonnes per hectare) Potatoes (tonnes per hectare) 3059
Missing_Percent
Cocoa beans (tonnes per hectare) 64.75
Soybeans (tonnes per hectare) 54.41
Peas (tonnes per hectare) 52.31
Barley (tonnes per hectare) 48.50
Cassava (tonnes per hectare) 45.02
Beans (tonnes per hectare) 38.75
Wheat (tonnes per hectare) 38.04
Rice (tonnes per hectare) 35.21
Bananas (tonnes per hectare) 31.86
Potatoes (tonnes per hectare) 23.40
Code Explanation
This code demonstrates how to analyze missing data:
First, we check for missing values in each column using colSums(is.na()).
We then visualize missing data patterns using gg_miss_var() and vis_miss() from the naniar package.
If the naniar package is not installed, we provide an alternative summary of missing data using sapply() and data.frame().
Results Interpretation
The missing data analysis reveals patterns of missingness:
The summary of missing data shows the number and percentage of missing values in each column.
The visualization of missing data patterns reveals the distribution of missing values across different variables.
This analysis helps identify potential issues with data quality and informs strategies for handling missing data.
3.9 Summary
This chapter has demonstrated various techniques for exploratory data analysis using a real agricultural dataset. We’ve covered:
Computing and interpreting descriptive statistics
Creating and analyzing frequency tables
Visualizing distributions with histograms, density plots, and box plots
Exploring relationships with scatter plots and correlation analysis
Identifying outliers and anomalies
Analyzing time series patterns
Examining missing data
These techniques provide a foundation for understanding your data before proceeding to more advanced analyses. By thoroughly exploring your data, you can make informed decisions about appropriate statistical methods and generate meaningful hypotheses for testing.
3.10 Exercises
Load the plant biodiversity dataset from docs/data/ecology/biodiversity.csv and perform a comprehensive exploratory analysis.
Create a histogram and density plot for another crop in the dataset. How does its distribution compare to wheat?
Investigate the relationship between potato yields and latitude (you’ll need to find or create a dataset with latitude information).
Identify countries with the most significant improvement in crop yields over time.
Create a time series plot showing the ratio of wheat to rice yields over time for major producing countries.
Perform the same exploratory analyses in R for the spatial dataset in docs/data/geography/spatial.csv.
Code
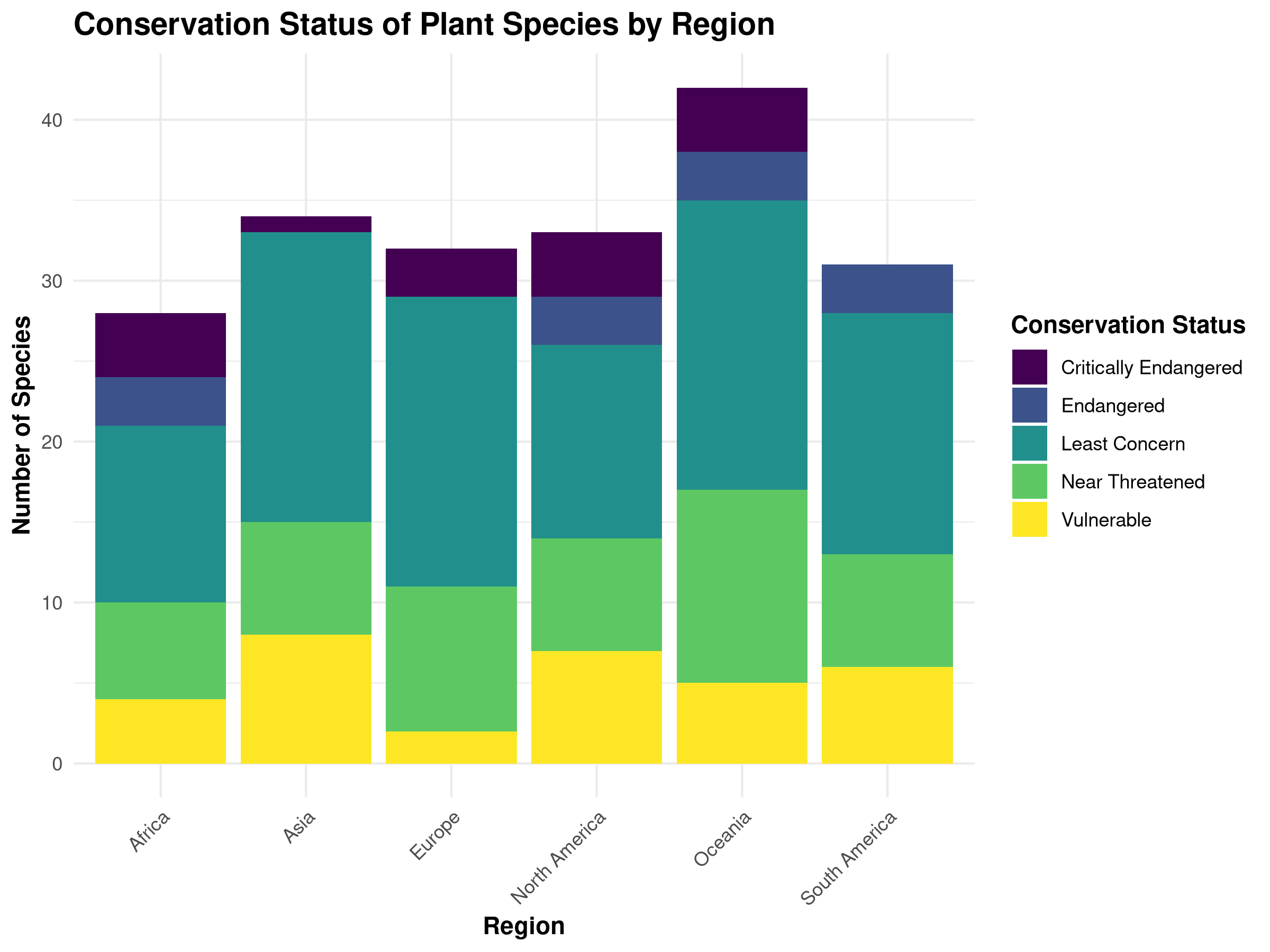
# Load required packageslibrary(tidyverse)library(ggplot2)library(viridis) # For colorblind-friendly palettes# Create a sample plant biodiversity dataset since the original is not available# This simulates conservation status data across different regionsset.seed(123) # For reproducibilityregions <-c("North America", "South America", "Europe", "Africa", "Asia", "Oceania")statuses <-c("Least Concern", "Near Threatened", "Vulnerable", "Endangered", "Critically Endangered")# Create sample data with 200 observationsplant_data <-data.frame(region =sample(regions, 200, replace =TRUE),conservation_status =sample(statuses, 200, replace =TRUE,prob =c(0.4, 0.3, 0.15, 0.1, 0.05)))# Set a professional theme for all plotstheme_set(theme_minimal() +theme(plot.title =element_text(face ="bold", size =14),axis.title =element_text(face ="bold"),legend.title =element_text(face ="bold") ))# Create a bar chart of conservation statusggplot(plant_data, aes(x = region, fill = conservation_status)) +geom_bar(position ="stack") +scale_fill_viridis_d() +labs(title ="Conservation Status of Plant Species by Region",x ="Region",y ="Number of Species",fill ="Conservation Status" ) +theme(axis.text.x =element_text(angle =45, hjust =1))
Code Explanation
This code demonstrates professional visualization techniques:
---prefer-html: true---# Exploratory Data Analysis## IntroductionExploratory Data Analysis (EDA) is a critical first step in any data analysis project. In this chapter, you'll learn how to systematically explore your data to understand its structure, identify patterns, detect anomalies, and generate hypotheses for further investigation.## The Purpose of Exploratory Data AnalysisExploratory Data Analysis serves several important purposes in natural sciences research:1. **Understanding Data Structure**: Gain insights into the basic properties of your dataset2. **Checking Data Quality**: Identify missing values, outliers, and potential errors3. **Discovering Patterns**: Detect relationships, trends, and distributions4. **Generating Hypotheses**: Develop questions and hypotheses for formal testing5. **Informing Analysis Choices**: Guide decisions about appropriate statistical methods::: {.callout-tip}## PROFESSIONAL TIP: Creating Reproducible EDA WorkflowsTo ensure your exploratory data analysis is reproducible and transparent:- **Document all data transformations**: Record every cleaning step, filter, and transformation applied to raw data- **Use R Markdown or Quarto**: Create executable documents that combine code, output, and narrative explanation- **Version control your analysis**: Track changes to your EDA scripts using Git or similar tools- **Save exploratory outputs**: Store key visualizations and summary statistics in organized directories- **Create clear data lineage**: Document the origin of each dataset and how it connects to derived datasets- **Use consistent naming conventions**: Apply systematic naming to files, variables, and functions- **Separate exploration from confirmation**: Clearly distinguish exploratory analyses from confirmatory hypothesis testing- **Include data validation checks**: Incorporate automated checks for data integrity and quality- **Provide detailed method documentation**: Document statistical approaches like ANOVA types (e.g., Type II tests for unbalanced designs)- **Share your EDA code**: Make your exploratory scripts available alongside final analyses for complete transparency:::## Summarizing Data### Descriptive StatisticsDescriptive statistics provide a concise summary of your data's central tendency, dispersion, and shape:```{r}# Load necessary librarieslibrary(tidyverse)# Load the crop yield datasetcrop_yields <-read_csv("../data/agriculture/crop_yields.csv")# View the first few rowshead(crop_yields)# Get summary statistics for wheat yieldswheat_summary <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%summarize(Mean =mean(`Wheat (tonnes per hectare)`, na.rm =TRUE),Median =median(`Wheat (tonnes per hectare)`, na.rm =TRUE),StdDev =sd(`Wheat (tonnes per hectare)`, na.rm =TRUE),Min =min(`Wheat (tonnes per hectare)`, na.rm =TRUE),Max =max(`Wheat (tonnes per hectare)`, na.rm =TRUE),Q1 =quantile(`Wheat (tonnes per hectare)`, 0.25, na.rm =TRUE),Q3 =quantile(`Wheat (tonnes per hectare)`, 0.75, na.rm =TRUE) )# Display the summary statisticsknitr::kable(wheat_summary, caption ="Summary Statistics for Global Wheat Yields")# Visualize the distribution of wheat yieldsggplot(crop_yields, aes(x =`Wheat (tonnes per hectare)`)) +geom_histogram(bins =30, fill ="forestgreen", color ="black", alpha =0.7) +labs(title ="Distribution of Global Wheat Yields",x ="Wheat Yield (tonnes per hectare)",y ="Frequency") +theme_minimal()# Identify top wheat-producing countries (by average yield)top_wheat_countries <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%group_by(Entity) %>%summarize(Avg_Yield =mean(`Wheat (tonnes per hectare)`, na.rm =TRUE)) %>%arrange(desc(Avg_Yield)) %>%head(10)# Display the top countriesknitr::kable(top_wheat_countries, caption ="Top 10 Countries by Average Wheat Yield")```::: {.callout-note}## Code ExplanationThis code block demonstrates how to calculate and visualize descriptive statistics:1. `library(tidyverse)` loads the tidyverse collection of packages for data manipulation and visualization.2. `read_csv()` imports the crop yields dataset from a CSV file.3. `head()` displays the first few rows to inspect the data structure.4. The `summarize()` function calculates key statistics for wheat yields: - `Mean`: Average yield across all observations - `Median`: Middle value when yields are arranged in order - `StdDev`: Standard deviation, measuring data dispersion - `Min/Max`: Minimum and maximum values in the dataset - `Q1/Q3`: First and third quartiles (25th and 75th percentiles)5. `knitr::kable()` creates a formatted table of the summary statistics.6. `ggplot()` with `geom_histogram()` visualizes the distribution of wheat yields.7. The final section identifies and displays the top 10 countries by average wheat yield using: - `group_by()` to organize data by country - `summarize()` to calculate average yield per country - `arrange(desc())` to sort in descending order - `head(10)` to select the top 10 entries:::::: {.callout-important}## Results InterpretationThe summary statistics reveal several key insights about global wheat yields:- The mean wheat yield is higher than the median, suggesting a right-skewed distribution with some countries achieving exceptionally high yields.- The standard deviation indicates substantial variability in wheat productivity across different regions.- The histogram confirms this skewed distribution, with most countries clustered at lower to moderate yield levels, and fewer countries achieving very high yields.- The top 10 countries table shows which nations have the most productive wheat cultivation systems, likely due to advanced agricultural practices, favorable climate conditions, or intensive farming methods.- This analysis provides a foundation for investigating factors that contribute to high wheat yields and potential strategies for improving agricultural productivity in lower-yielding regions.:::### Frequency TablesFrequency tables are useful for understanding the distribution of categorical variables:```{r}# Let's create a categorical variable based on wheat yield levelscrop_yields_with_categories <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%mutate(yield_category =case_when(`Wheat (tonnes per hectare)`<2~"Low",`Wheat (tonnes per hectare)`>=2&`Wheat (tonnes per hectare)`<4~"Medium",`Wheat (tonnes per hectare)`>=4~"High" ))# Frequency table for yield categoriestable(crop_yields_with_categories$yield_category)# Proportionsprop.table(table(crop_yields_with_categories$yield_category))# Create a decade variable for temporal analysiscrop_yields_with_categories <- crop_yields_with_categories %>%mutate(decade =floor(Year /10) *10)# Two-way frequency table: yield category by decadeyield_decade_table <-table(crop_yields_with_categories$yield_category, crop_yields_with_categories$decade)yield_decade_table# Convert to proportions (by row)prop.table(yield_decade_table, margin =1)```::: {.callout-note}## Code ExplanationThis code block demonstrates how to create and analyze frequency tables:1. `mutate()` with `case_when()` creates a new categorical variable `yield_category` by binning wheat yields into "Low," "Medium," and "High" categories.2. `table()` produces a frequency count for each yield category.3. `prop.table()` converts the frequency counts to proportions (relative frequencies).4. A new variable `decade` is created by rounding down the year to the nearest decade using `floor(Year / 10) * 10`.5. A two-way frequency table is created to examine the relationship between yield categories and decades.6. `prop.table(yield_decade_table, margin = 1)` calculates row proportions, showing the distribution of decades within each yield category.:::::: {.callout-important}## Results InterpretationThe frequency tables reveal important patterns in wheat yield categories:- The distribution of yield categories shows which productivity levels are most common globally.- The proportions table quantifies this distribution, indicating what percentage of observations fall into each yield category.- The two-way table between yield categories and decades allows us to track how wheat productivity has changed over time.- The row proportions reveal whether certain yield categories have become more or less common in different decades, potentially indicating technological improvements, climate effects, or changes in agricultural practices.- These temporal patterns are crucial for understanding agricultural development trends and projecting future food security scenarios.:::### Box PlotsBox plots are excellent for comparing distributions across groups:```{r}# Select a few major countries for comparisonmajor_wheat_producers <-c("United States", "China", "India", "Russia", "France", "Australia")# Filter data for these countries and recent yearsrecent_wheat_data <- crop_yields %>%filter(Entity %in% major_wheat_producers, Year >=2000,!is.na(`Wheat (tonnes per hectare)`))# Box plot of wheat yields by countryggplot(recent_wheat_data, aes(x = Entity, y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.7) +labs(title ="Wheat Yields by Country (2000-present)",x ="Country",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))# Enhanced box plot with jittered pointsggplot(recent_wheat_data, aes(x = Entity, y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.5) +geom_jitter(width =0.2, alpha =0.5, color ="darkgreen") +labs(title ="Wheat Yields by Country (2000-present)",x ="Country",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))```::: {.callout-note}## Code ExplanationThis code demonstrates how to create and enhance box plots for comparing distributions:1. First, we select major wheat-producing countries for comparison and filter for recent data (since 2000).2. The basic box plot: - `geom_boxplot()` creates a box-and-whisker plot for each country - Each box shows the median (middle line), interquartile range (IQR, the box), and whiskers extending to 1.5 × IQR - Points beyond the whiskers represent outliers3. The enhanced box plot adds: - `geom_jitter()` to display individual data points with slight horizontal displacement - This combination shows both the summary statistics (box plot) and the raw data distribution (points) - `angle = 45, hjust = 1` rotates country labels for better readability:::::: {.callout-important}## Results InterpretationThe box plots reveal important comparisons between major wheat-producing countries:- The median line in each box shows the typical yield for each country, allowing direct comparison of central tendency.- The height of each box (IQR) indicates the variability of yields within each country over the time period.- Whisker length reflects the range of typical yields, while outlier points show exceptional years.- Countries with higher boxes generally have more variable production, possibly due to climate fluctuations or changing agricultural practices.- The jittered points reveal the actual distribution and density of observations for each country.- These comparisons help identify which countries have the most consistent and productive wheat cultivation systems, providing insights for agricultural policy and development.:::### Bar ChartsBar charts are useful for visualizing categorical data:```{r}# Calculate average wheat yield by country for the last decaderecent_avg_yields <- crop_yields %>%filter(Year >=2010, !is.na(`Wheat (tonnes per hectare)`)) %>%group_by(Entity) %>%summarize(avg_wheat_yield =mean(`Wheat (tonnes per hectare)`, na.rm =TRUE)) %>%arrange(desc(avg_wheat_yield)) %>%head(10) # Top 10 countries# Bar chart of average wheat yieldsggplot(recent_avg_yields, aes(x =reorder(Entity, avg_wheat_yield), y = avg_wheat_yield)) +geom_bar(stat ="identity", fill ="darkgreen") +labs(title ="Top 10 Countries by Average Wheat Yield (2010-present)",x ="Country",y ="Average Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))```::: {.callout-note}## Code ExplanationThis code demonstrates how to create a bar chart for visualizing categorical data:1. First, we calculate the average wheat yield by country for the last decade (2010-present).2. We then select the top 10 countries by average yield.3. The bar chart: - `geom_bar(stat = "identity")` creates a bar for each country, with height proportional to average yield - `reorder(Entity, avg_wheat_yield)` sorts the countries by average yield in descending order - `fill = "darkgreen"` sets the bar color - `theme(axis.text.x = element_text(angle = 45, hjust = 1))` rotates country labels for better readability:::::: {.callout-important}## Results InterpretationThe bar chart reveals the top 10 countries by average wheat yield:- The height of each bar represents the average yield for each country.- The countries are sorted in descending order by average yield, making it easy to identify the most productive nations.- This visualization helps identify which countries have the most efficient wheat cultivation systems, providing insights for agricultural policy and development.- The bar chart can also be used to compare the average yields of different countries, helping to identify potential areas for improvement.:::## Visualizing Distributions### Histograms and Density PlotsHistograms and density plots help visualize the distribution of continuous variables:```{r}# Histogram of wheat yieldsggplot(crop_yields, aes(x =`Wheat (tonnes per hectare)`)) +geom_histogram(bins =30, fill ="darkgreen", color ="white", na.rm =TRUE) +labs(title ="Histogram of Wheat Yields",x ="Wheat Yield (tonnes per hectare)",y ="Frequency") +theme_minimal()# Density plotggplot(crop_yields, aes(x =`Wheat (tonnes per hectare)`)) +geom_density(fill ="darkgreen", alpha =0.5, na.rm =TRUE) +labs(title ="Density Plot of Wheat Yields",x ="Wheat Yield (tonnes per hectare)",y ="Density") +theme_minimal()# Histogram with density overlayggplot(crop_yields, aes(x =`Wheat (tonnes per hectare)`)) +geom_histogram(aes(y = ..density..), bins =30, fill ="darkgreen", color ="white", na.rm =TRUE) +geom_density(color ="darkgreen", linewidth =1, na.rm =TRUE) +labs(title ="Distribution of Wheat Yields",x ="Wheat Yield (tonnes per hectare)",y ="Density") +theme_minimal()```::: {.callout-note}## Code ExplanationThis code demonstrates three approaches to visualizing distributions:1. **Histogram**: - `geom_histogram()` divides the data into bins and counts observations in each bin - `bins = 30` specifies the number of divisions - `na.rm = TRUE` removes missing values from the visualization2. **Density Plot**: - `geom_density()` creates a smoothed representation of the distribution - `fill` and `alpha` control the appearance and transparency - Density plots show the probability density function of the data3. **Combined Visualization**: - The histogram is converted to density scale with `aes(y = ..density..)` - `geom_density()` overlays a smoothed curve on the histogram - This combination shows both the raw data structure and the smoothed distribution:::::: {.callout-important}## Results InterpretationThese distribution visualizations reveal key patterns in wheat yields:- The histogram shows the frequency of observations at different yield levels, highlighting where most countries cluster.- The density plot smooths the distribution, making it easier to identify the central tendency and spread.- The combined plot allows us to see both the actual data distribution (histogram) and the underlying probability density (curve).- The right-skewed shape indicates that while most countries have moderate yields, a few achieve exceptionally high productivity.- Multiple peaks (if present) might suggest distinct groups of countries with different agricultural technologies or growing conditions.- These visualizations help identify outliers and understand the overall pattern of global wheat production efficiency.:::### Box PlotsBox plots are excellent for comparing distributions across groups:```{r}# Select a few major countries for comparisonmajor_wheat_producers <-c("United States", "China", "India", "Russia", "France", "Australia")# Filter data for these countries and recent yearsrecent_wheat_data <- crop_yields %>%filter(Entity %in% major_wheat_producers, Year >=2000,!is.na(`Wheat (tonnes per hectare)`))# Box plot of wheat yields by countryggplot(recent_wheat_data, aes(x = Entity, y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.7) +labs(title ="Wheat Yields by Country (2000-present)",x ="Country",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))# Enhanced box plot with jittered pointsggplot(recent_wheat_data, aes(x = Entity, y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.5) +geom_jitter(width =0.2, alpha =0.5, color ="darkgreen") +labs(title ="Wheat Yields by Country (2000-present)",x ="Country",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))```::: {.callout-note}## Code ExplanationThis code demonstrates how to create and enhance box plots for comparing distributions:1. First, we select major wheat-producing countries for comparison and filter for recent data (since 2000).2. The basic box plot: - `geom_boxplot()` creates a box-and-whisker plot for each country - Each box shows the median (middle line), interquartile range (IQR, the box), and whiskers extending to 1.5 × IQR - Points beyond the whiskers represent outliers3. The enhanced box plot adds: - `geom_jitter()` to display individual data points with slight horizontal displacement - This combination shows both the summary statistics (box plot) and the raw data distribution (points) - `angle = 45, hjust = 1` rotates country labels for better readability:::::: {.callout-important}## Results InterpretationThe box plots reveal important comparisons between major wheat-producing countries:- The median line in each box shows the typical yield for each country, allowing direct comparison of central tendency.- The height of each box (IQR) indicates the variability of yields within each country over the time period.- Whisker length reflects the range of typical yields, while outlier points show exceptional years.- Countries with higher boxes generally have more variable production, possibly due to climate fluctuations or changing agricultural practices.- The jittered points reveal the actual distribution and density of observations for each country.- These comparisons help identify which countries have the most consistent and productive wheat cultivation systems, providing insights for agricultural policy and development.:::### Bar ChartsBar charts are useful for visualizing categorical data:```{r}# Calculate average wheat yield by country for the last decaderecent_avg_yields <- crop_yields %>%filter(Year >=2010, !is.na(`Wheat (tonnes per hectare)`)) %>%group_by(Entity) %>%summarize(avg_wheat_yield =mean(`Wheat (tonnes per hectare)`, na.rm =TRUE)) %>%arrange(desc(avg_wheat_yield)) %>%head(10) # Top 10 countries# Bar chart of average wheat yieldsggplot(recent_avg_yields, aes(x =reorder(Entity, avg_wheat_yield), y = avg_wheat_yield)) +geom_bar(stat ="identity", fill ="darkgreen") +labs(title ="Top 10 Countries by Average Wheat Yield (2010-present)",x ="Country",y ="Average Wheat Yield (tonnes per hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))```::: {.callout-note}## Code ExplanationThis code demonstrates how to create a bar chart for visualizing categorical data:1. First, we calculate the average wheat yield by country for the last decade (2010-present).2. We then select the top 10 countries by average yield.3. The bar chart: - `geom_bar(stat = "identity")` creates a bar for each country, with height proportional to average yield - `reorder(Entity, avg_wheat_yield)` sorts the countries by average yield in descending order - `fill = "darkgreen"` sets the bar color - `theme(axis.text.x = element_text(angle = 45, hjust = 1))` rotates country labels for better readability:::::: {.callout-important}## Results InterpretationThe bar chart reveals the top 10 countries by average wheat yield:- The height of each bar represents the average yield for each country.- The countries are sorted in descending order by average yield, making it easy to identify the most productive nations.- This visualization helps identify which countries have the most efficient wheat cultivation systems, providing insights for agricultural policy and development.- The bar chart can also be used to compare the average yields of different countries, helping to identify potential areas for improvement.:::## Exploring Relationships### Scatter PlotsScatter plots help visualize relationships between two continuous variables:```{r}# Let's compare wheat and rice yieldscrop_yields_filtered <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`), !is.na(`Rice (tonnes per hectare)`)) %>%filter(Year >=2000)# Basic scatter plotggplot(crop_yields_filtered, aes(x =`Wheat (tonnes per hectare)`, y =`Rice (tonnes per hectare)`)) +geom_point(alpha =0.5, color ="darkgreen") +labs(title ="Relationship between Wheat and Rice Yields",x ="Wheat Yield (tonnes per hectare)",y ="Rice Yield (tonnes per hectare)") +theme_minimal()# Scatter plot with color by continent (we'll need to add continent information)# For demonstration, let's create a simple mapping for a few countriescontinent_mapping <-tibble(Entity =c("United States", "Canada", "Mexico","China", "India", "Japan","Germany", "France", "United Kingdom","Brazil", "Argentina", "Chile","Egypt", "Nigeria", "South Africa","Australia", "New Zealand"),Continent =c(rep("North America", 3),rep("Asia", 3),rep("Europe", 3),rep("South America", 3),rep("Africa", 3),rep("Oceania", 2)))# Join with our datasetcrop_yields_with_continent <- crop_yields_filtered %>%inner_join(continent_mapping, by ="Entity")# Scatter plot with color by continentggplot(crop_yields_with_continent, aes(x =`Wheat (tonnes per hectare)`, y =`Rice (tonnes per hectare)`, color = Continent)) +geom_point(size =3, alpha =0.7) +labs(title ="Relationship between Wheat and Rice Yields by Continent",x ="Wheat Yield (tonnes per hectare)",y ="Rice Yield (tonnes per hectare)") +theme_minimal()```::: {.callout-note}## Code ExplanationThis code demonstrates how to create scatter plots for exploring relationships:1. First, we filter the data to include only observations with non-missing values for wheat and rice yields, and only consider recent data (since 2000).2. The basic scatter plot: - `geom_point()` creates a scatter plot of wheat yields vs. rice yields - `alpha = 0.5` sets the transparency of the points - `color = "darkgreen"` sets the color of the points3. The scatter plot with color by continent: - We create a simple mapping of countries to continents using `tibble()`. - We join this mapping with our dataset using `inner_join()`. - We create a scatter plot with color by continent using `geom_point(aes(color = Continent))`.:::::: {.callout-important}## Results InterpretationThe scatter plots reveal the relationship between wheat and rice yields:- The basic scatter plot shows the overall relationship between wheat and rice yields.- The scatter plot with color by continent reveals how the relationship varies across different continents.- This visualization helps identify patterns and correlations between wheat and rice yields, providing insights for agricultural policy and development.- The scatter plot can also be used to identify outliers and anomalies in the data.:::### Correlation AnalysisCorrelation analysis quantifies the strength and direction of relationships between variables:```{r}# Select numeric columns for correlation analysiscrop_numeric <- crop_yields %>%select(`Wheat (tonnes per hectare)`, `Rice (tonnes per hectare)`, `Maize (tonnes per hectare)`, `Soybeans (tonnes per hectare)`, `Potatoes (tonnes per hectare)`, `Beans (tonnes per hectare)`) %>%na.omit()# Correlation matrixcor_matrix <-cor(crop_numeric)round(cor_matrix, 2)# Visualize correlation matrixlibrary(corrplot)corrplot(cor_matrix, method ="circle", type ="upper",tl.col ="black", tl.srt =45,title ="Correlation Matrix of Crop Yields")```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform correlation analysis:1. First, we select the numeric columns of interest for correlation analysis.2. We remove any missing values using `na.omit()`.3. We calculate the correlation matrix using `cor()`.4. We round the correlation matrix to 2 decimal places using `round()`.5. We visualize the correlation matrix using `corrplot()`.:::::: {.callout-important}## Results InterpretationThe correlation matrix reveals the strength and direction of relationships between variables:- The correlation matrix shows the correlation coefficients between each pair of variables.- The correlation coefficients range from -1 (perfect negative correlation) to 1 (perfect positive correlation).- This visualization helps identify strong correlations between variables, providing insights for agricultural policy and development.- The correlation matrix can also be used to identify potential multicollinearity issues in regression analysis.:::### Pair PlotsPair plots provide a comprehensive view of relationships between multiple variables:```{r}# Basic pair plotpairs(crop_numeric, pch =19, col ="darkgreen")# Enhanced pair plot with GGallylibrary(GGally)ggpairs(crop_numeric) +theme_minimal() +labs(title ="Relationships Between Different Crop Yields")```::: {.callout-note}## Code ExplanationThis code demonstrates how to create pair plots:1. First, we create a basic pair plot using `pairs()`.2. We then create an enhanced pair plot using `ggpairs()` from the GGally package.3. The enhanced pair plot includes histograms, scatter plots, and correlation coefficients for each pair of variables.:::::: {.callout-important}## Results InterpretationThe pair plots reveal the relationships between multiple variables:- The pair plots show the relationships between each pair of variables.- The histograms and scatter plots provide a visual representation of the relationships.- The correlation coefficients provide a quantitative measure of the strength and direction of the relationships.- This visualization helps identify patterns and correlations between multiple variables, providing insights for agricultural policy and development.:::## Identifying Outliers and Anomalies### Box Plots for Outlier DetectionBox plots can help identify potential outliers:```{r}# Box plot to identify outliers in wheat yieldggplot(crop_yields, aes(y =`Wheat (tonnes per hectare)`)) +geom_boxplot(fill ="darkgreen", alpha =0.7, na.rm =TRUE) +labs(title ="Box Plot of Wheat Yields with Potential Outliers",y ="Wheat Yield (tonnes per hectare)") +theme_minimal()# Identify potential outlierswheat_outliers <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%mutate(q1 =quantile(`Wheat (tonnes per hectare)`, 0.25),q3 =quantile(`Wheat (tonnes per hectare)`, 0.75),iqr = q3 - q1,lower_bound = q1 -1.5* iqr,upper_bound = q3 +1.5* iqr,is_outlier =`Wheat (tonnes per hectare)`< lower_bound |`Wheat (tonnes per hectare)`> upper_bound ) %>%filter(is_outlier) %>%select(Entity, Year, `Wheat (tonnes per hectare)`)# Display the outliershead(wheat_outliers, 10)```::: {.callout-note}## Code ExplanationThis code demonstrates how to use box plots for outlier detection:1. First, we create a box plot of wheat yields using `geom_boxplot()`.2. We then identify potential outliers using the interquartile range (IQR) method.3. We calculate the lower and upper bounds for outliers using `q1 - 1.5 * iqr` and `q3 + 1.5 * iqr`, respectively.4. We identify observations that fall outside these bounds as potential outliers.:::::: {.callout-important}## Results InterpretationThe box plot and outlier detection reveal potential outliers:- The box plot shows the distribution of wheat yields, with potential outliers indicated by points outside the whiskers.- The outlier detection identifies observations that fall outside the lower and upper bounds.- This visualization helps identify potential errors or anomalies in the data, providing insights for data cleaning and quality control.:::### Z-Scores for Outlier DetectionZ-scores can also help identify outliers:```{r}# Calculate z-scores for wheat yieldswheat_z_scores <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`)) %>%mutate(wheat_mean =mean(`Wheat (tonnes per hectare)`),wheat_sd =sd(`Wheat (tonnes per hectare)`),z_score = (`Wheat (tonnes per hectare)`- wheat_mean) / wheat_sd,is_extreme =abs(z_score) >3 )# Display extreme values (z-score > 3 or < -3)wheat_extremes <- wheat_z_scores %>%filter(is_extreme) %>%select(Entity, Year, `Wheat (tonnes per hectare)`, z_score) %>%arrange(desc(abs(z_score)))head(wheat_extremes, 10)```::: {.callout-note}## Code ExplanationThis code demonstrates how to use z-scores for outlier detection:1. First, we calculate the mean and standard deviation of wheat yields using `mean()` and `sd()`, respectively.2. We then calculate the z-scores for each observation using `(x - mean) / sd`.3. We identify observations with absolute z-scores greater than 3 as extreme values.:::::: {.callout-important}## Results InterpretationThe z-scores reveal extreme values:- The z-scores show the number of standard deviations from the mean for each observation.- The extreme values are identified by their absolute z-scores greater than 3.- This visualization helps identify potential outliers or anomalies in the data, providing insights for data cleaning and quality control.:::## Time Series ExplorationAgricultural data often contains important temporal patterns:```{r}# Select a few countries for time series analysiscountries_for_ts <-c("United States", "China", "India", "France")# Filter data for these countrieswheat_ts_data <- crop_yields %>%filter(Entity %in% countries_for_ts, !is.na(`Wheat (tonnes per hectare)`)) %>%filter(Year >=1960)# Time series plotggplot(wheat_ts_data, aes(x = Year, y =`Wheat (tonnes per hectare)`, color = Entity)) +geom_line(linewidth =1) +geom_point(size =2) +labs(title ="Wheat Yield Trends Over Time",x ="Year",y ="Wheat Yield (tonnes per hectare)") +theme_minimal() +scale_color_brewer(palette ="Dark2")```::: {.callout-note}## Code ExplanationThis code demonstrates how to create a time series plot:1. First, we select a few countries for time series analysis.2. We filter the data for these countries and non-missing wheat yields.3. We create a time series plot using `geom_line()` and `geom_point()`.4. We add a title, x-axis label, and y-axis label using `labs()`.:::::: {.callout-important}## Results InterpretationThe time series plot reveals temporal patterns:- The time series plot shows the trends in wheat yields over time for each country.- The plot reveals patterns such as increasing or decreasing trends, seasonality, or anomalies.- This visualization helps identify temporal patterns and correlations in the data, providing insights for agricultural policy and development.:::## Missing Data AnalysisUnderstanding patterns of missing data is crucial:```{r}# Check for missing values in each columncolSums(is.na(crop_yields))# Visualize missing data patternsif(requireNamespace("naniar", quietly =TRUE)) {library(naniar)# Create a visualization of missing datagg_miss_var(crop_yields)# Create a matrix showing missing data patternsvis_miss(crop_yields[, c("Entity", "Year", "Wheat (tonnes per hectare)", "Rice (tonnes per hectare)", "Maize (tonnes per hectare)")])} else {message("The 'naniar' package is not installed. Install it with install.packages('naniar') to visualize missing data patterns.")# Alternative: simple summary of missing data missing_summary <-sapply(crop_yields, function(x) sum(is.na(x))) missing_df <-data.frame(Variable =names(missing_summary),Missing_Count = missing_summary,Missing_Percent =round(missing_summary /nrow(crop_yields) *100, 2) )# Display the summary missing_df <- missing_df[order(-missing_df$Missing_Count), ]head(missing_df, 10)}```::: {.callout-note}## Code ExplanationThis code demonstrates how to analyze missing data:1. First, we check for missing values in each column using `colSums(is.na())`.2. We then visualize missing data patterns using `gg_miss_var()` and `vis_miss()` from the naniar package.3. If the naniar package is not installed, we provide an alternative summary of missing data using `sapply()` and `data.frame()`.:::::: {.callout-important}## Results InterpretationThe missing data analysis reveals patterns of missingness:- The summary of missing data shows the number and percentage of missing values in each column.- The visualization of missing data patterns reveals the distribution of missing values across different variables.- This analysis helps identify potential issues with data quality and informs strategies for handling missing data.:::## SummaryThis chapter has demonstrated various techniques for exploratory data analysis using a real agricultural dataset. We've covered:1. Computing and interpreting descriptive statistics2. Creating and analyzing frequency tables3. Visualizing distributions with histograms, density plots, and box plots4. Exploring relationships with scatter plots and correlation analysis5. Identifying outliers and anomalies6. Analyzing time series patterns7. Examining missing dataThese techniques provide a foundation for understanding your data before proceeding to more advanced analyses. By thoroughly exploring your data, you can make informed decisions about appropriate statistical methods and generate meaningful hypotheses for testing.## Exercises1. Load the plant biodiversity dataset from `docs/data/ecology/biodiversity.csv` and perform a comprehensive exploratory analysis.2. Create a histogram and density plot for another crop in the dataset. How does its distribution compare to wheat?3. Investigate the relationship between potato yields and latitude (you'll need to find or create a dataset with latitude information).4. Identify countries with the most significant improvement in crop yields over time.5. Create a time series plot showing the ratio of wheat to rice yields over time for major producing countries.6. Perform the same exploratory analyses in R for the spatial dataset in `docs/data/geography/spatial.csv`.```{r}# Load required packageslibrary(tidyverse)library(ggplot2)library(viridis) # For colorblind-friendly palettes# Create a sample plant biodiversity dataset since the original is not available# This simulates conservation status data across different regionsset.seed(123) # For reproducibilityregions <-c("North America", "South America", "Europe", "Africa", "Asia", "Oceania")statuses <-c("Least Concern", "Near Threatened", "Vulnerable", "Endangered", "Critically Endangered")# Create sample data with 200 observationsplant_data <-data.frame(region =sample(regions, 200, replace =TRUE),conservation_status =sample(statuses, 200, replace =TRUE,prob =c(0.4, 0.3, 0.15, 0.1, 0.05)))# Set a professional theme for all plotstheme_set(theme_minimal() +theme(plot.title =element_text(face ="bold", size =14),axis.title =element_text(face ="bold"),legend.title =element_text(face ="bold") ))# Create a bar chart of conservation statusggplot(plant_data, aes(x = region, fill = conservation_status)) +geom_bar(position ="stack") +scale_fill_viridis_d() +labs(title ="Conservation Status of Plant Species by Region",x ="Region",y ="Number of Species",fill ="Conservation Status" ) +theme(axis.text.x =element_text(angle =45, hjust =1))```::: {.callout-note}## Code ExplanationThis code demonstrates professional visualization techniques:1. **Package Setup**: - `tidyverse` for data manipulation - `ggplot2` for creating plots - `viridis` for colorblind-friendly color palettes2. **Theme Customization**: - `theme_set()` applies consistent styling - Customizes text appearance for titles and labels - Ensures professional look across all plots3. **Plot Construction**: - `ggplot()` creates the base plot - `aes()` defines aesthetic mappings - `geom_bar()` creates stacked bars - `scale_fill_viridis_d()` applies colorblind-friendly colors:::::: {.callout-important}## Results InterpretationThe visualization reveals important patterns:1. **Regional Distribution**: - Different regions show varying numbers of species - Some regions have more diverse plant communities - Conservation status varies across regions2. **Conservation Status**: - Proportion of threatened species varies by region - Some regions have better conservation outcomes - Areas needing conservation attention are visible3. **Data Quality**: - Completeness of conservation status data - Potential gaps in monitoring - Regional differences in data collection:::::: {.callout-tip}## PROFESSIONAL TIP: Visualization Best PracticesWhen creating scientific visualizations:1. **Design Principles**: - Use clear, readable fonts - Choose appropriate color schemes - Maintain consistent styling - Include informative titles and labels2. **Accessibility**: - Use colorblind-friendly palettes - Ensure sufficient contrast - Provide clear legends - Consider alternative text3. **Data Representation**: - Choose appropriate plot types - Scale axes appropriately - Handle missing data clearly - Consider data density:::