This chapter explores common statistical tests used in natural sciences research. Building on the hypothesis testing framework introduced in the previous chapter, we’ll examine specific tests for different research scenarios and data types.
5.2 Choosing the Right Statistical Test
Selecting the appropriate statistical test depends on several factors:
Research Question: What you’re trying to determine
Data Type: Categorical, continuous, or ordinal
Number of Groups: One, two, or multiple groups
Data Distribution: Normal or non-normal
Independence: Whether observations are independent or related
5.2.1 Decision Tree for Common Tests
Code Explanation
This code creates a decision tree for statistical test selection:
Package Setup:
Uses DiagrammeR for creating flowcharts
Defines node styles and attributes
Sets up the graph structure
Node Structure:
Main categories: One Variable, Two Variables, Multiple Variables
Subcategories for different data types
Specific tests for each scenario
Connections:
Shows logical flow between decisions
Links tests to appropriate scenarios
Guides test selection process
Results Interpretation
The decision tree provides a systematic approach to test selection:
Test Categories:
Parametric vs. non-parametric tests
Tests for different data types
Tests for different sample sizes
Selection Criteria:
Data distribution (normal vs. non-normal)
Number of variables
Type of variables (continuous vs. categorical)
Sample independence
Test Properties:
Assumptions of each test
Appropriate use cases
Limitations and considerations
PROFESSIONAL TIP: Statistical Test Selection
When choosing statistical tests:
Data Characteristics:
Check data distribution
Verify assumptions
Consider sample size
Evaluate data types
Research Design:
Match test to research question
Consider experimental design
Account for dependencies
Plan for multiple comparisons
Test Selection Process:
Start with research question
Identify data characteristics
Choose appropriate test
Verify assumptions
Consider alternatives
5.3 Parametric vs. Non-Parametric Tests
5.3.1 Parametric Tests
Parametric tests make assumptions about the underlying population distribution, typically that the data follows a normal distribution. Common parametric tests include:
t-tests
ANOVA
Pearson correlation
Linear regression
5.3.2 Non-Parametric Tests
Non-parametric tests make fewer assumptions about the population distribution and are useful when data doesn’t meet the assumptions of parametric tests. Common non-parametric tests include:
Mann-Whitney U test
Wilcoxon signed-rank test
Kruskal-Wallis test
Spearman correlation
5.3.3 Checking Assumptions
Before applying a parametric test, it’s essential to check if your data meets the necessary assumptions. Let’s use our crop yield dataset to demonstrate:
Code
# Load necessary librarieslibrary(tidyverse)# Load the crop yield datasetcrop_yields <-read_csv("../data/agriculture/crop_yields.csv")# View column names to see how R has formatted themnames(crop_yields)
[1] "Entity" "Code"
[3] "Year" "Wheat (tonnes per hectare)"
[5] "Rice (tonnes per hectare)" "Maize (tonnes per hectare)"
[7] "Soybeans (tonnes per hectare)" "Potatoes (tonnes per hectare)"
[9] "Beans (tonnes per hectare)" "Peas (tonnes per hectare)"
[11] "Cassava (tonnes per hectare)" "Barley (tonnes per hectare)"
[13] "Cocoa beans (tonnes per hectare)" "Bananas (tonnes per hectare)"
Code
# Extract wheat yields for analysiswheat_yields <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) & Year >=1960) %>%select(Entity, Year, `Wheat (tonnes per hectare)`)# View the first few rowsknitr::kable(head(wheat_yields),caption ="Sample of Wheat Yield Data",align =c("l", "c", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Sample of Wheat Yield Data
Entity
Year
Wheat (tonnes per hectare)
Afghanistan
1961
1.0220
Afghanistan
1962
0.9735
Afghanistan
1963
0.8317
Afghanistan
1964
0.9510
Afghanistan
1965
0.9723
Afghanistan
1966
0.8666
Code
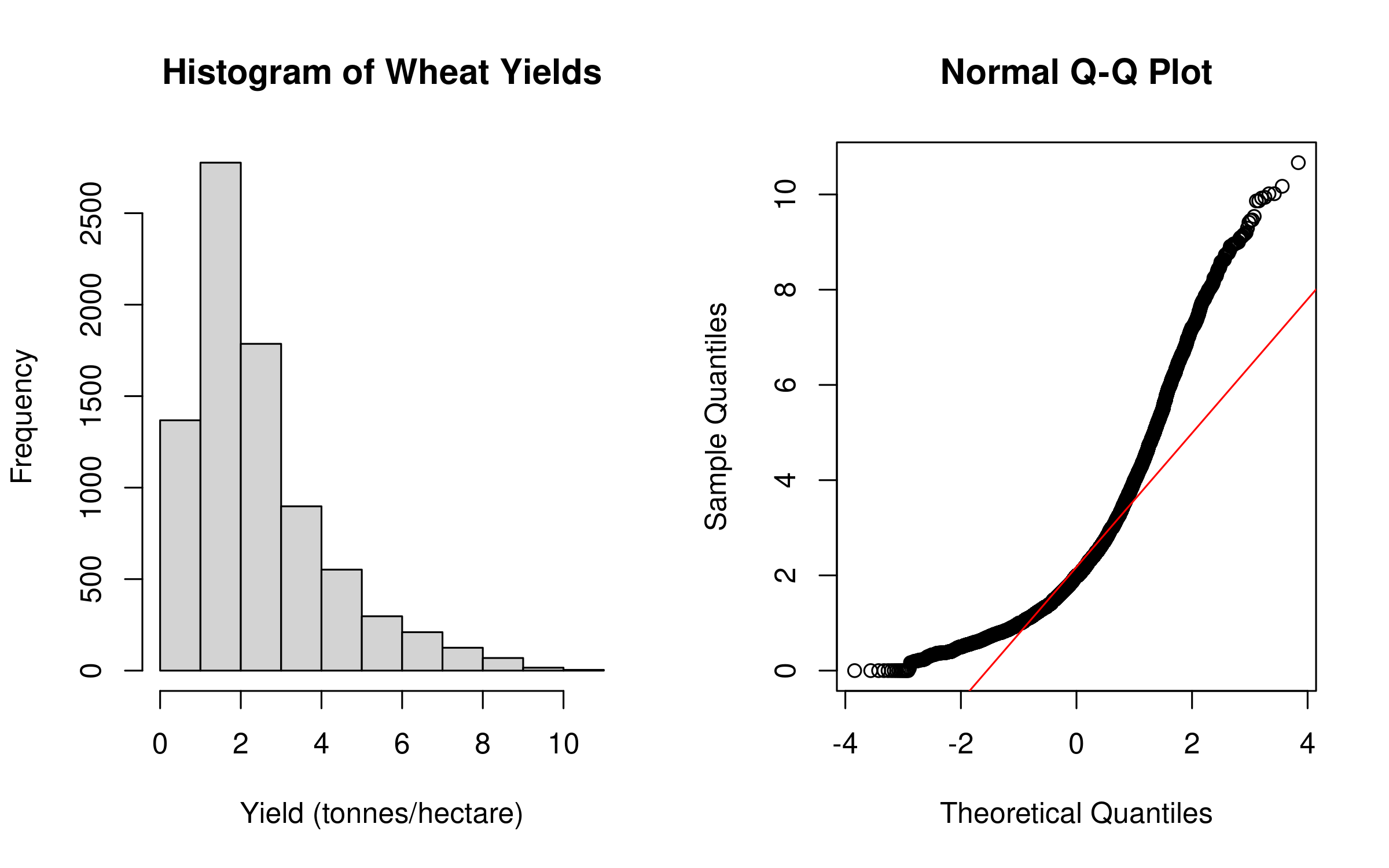
# Check for normality# Visual methodspar(mfrow =c(1, 2))hist(wheat_yields$`Wheat (tonnes per hectare)`, main ="Histogram of Wheat Yields", xlab ="Yield (tonnes/hectare)")qqnorm(wheat_yields$`Wheat (tonnes per hectare)`); qqline(wheat_yields$`Wheat (tonnes per hectare)`, col ="red")
Code
# Statistical test for normalityshapiro_result <-shapiro.test(sample(wheat_yields$`Wheat (tonnes per hectare)`, min(5000, length(wheat_yields$`Wheat (tonnes per hectare)`))))# Create a formatted table of the resultsshapiro_table <-data.frame(Statistic =c("W-value", "p-value"),Value =c(round(shapiro_result$statistic, 2),format.pval(shapiro_result$p.value, digits =3) ))# Display the formatted tableknitr::kable(shapiro_table,caption ="Shapiro-Wilk Normality Test Results: Wheat Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
This code demonstrates how to check the normality assumption for parametric tests:
Data Preparation: Imports and filters the dataset, removing missing values
Visual Assessment: Creates histogram and Q-Q plot to visually assess normality
Statistical Testing: Uses Shapiro-Wilk test to formally test for normality
Result Presentation: Formats results in clear, publication-ready tables
Results Interpretation
The normality assessment reveals a right-skewed distribution of wheat yields, confirmed by both visual inspection and the significant Shapiro-Wilk test (p < 0.001). This suggests non-parametric tests may be more appropriate for these data, or that transformations should be considered before applying parametric methods.
5.4 Tests for Comparing Groups
5.4.1 t-Tests
5.4.1.1 Independent Samples t-Test
Used to compare means between two independent groups. Let’s compare wheat yields between two time periods:
Code
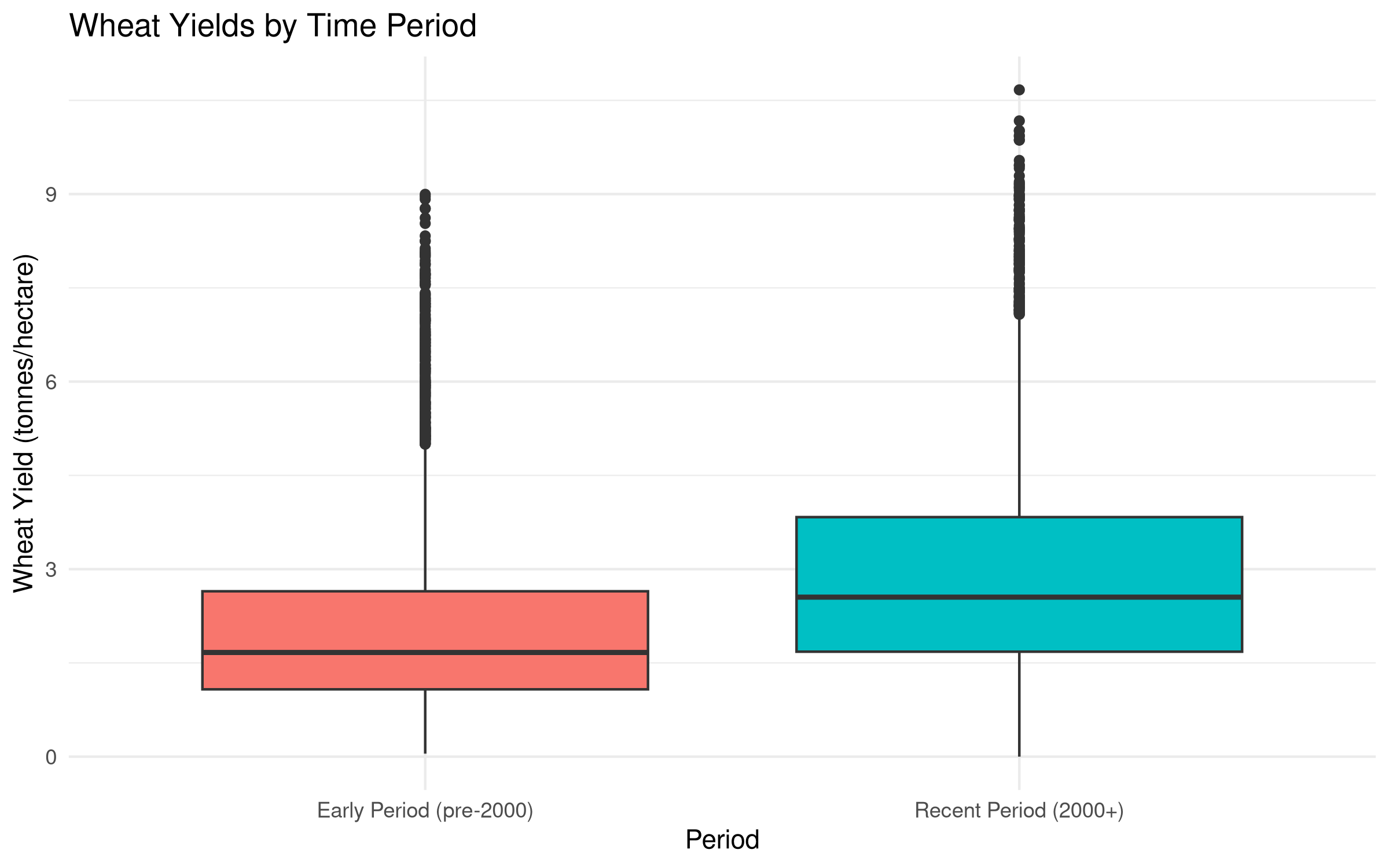
# Create two groups: early period (before 2000) and recent period (2000 onwards)crop_yields_grouped <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) & Year >=1960) %>%mutate(period =ifelse(Year <2000, "Early Period (pre-2000)", "Recent Period (2000+)"))# Visualize the dataggplot(crop_yields_grouped, aes(x = period, y =`Wheat (tonnes per hectare)`, fill = period)) +geom_boxplot() +labs(title ="Wheat Yields by Time Period",x ="Period",y ="Wheat Yield (tonnes/hectare)") +theme_minimal() +theme(legend.position ="none")
Code
# Perform independent samples t-test using formula interface with backtickst_test_result <-t.test(`Wheat (tonnes per hectare)`~ period, data = crop_yields_grouped)# Create a formatted table of the resultst_test_table <-data.frame(Statistic =c("t-value", "Degrees of Freedom", "p-value", "Mean Difference", "95% CI Lower", "95% CI Upper"),Value =c(round(t_test_result$statistic, 3),round(t_test_result$parameter, 1),format.pval(t_test_result$p.value, digits =3),round(diff(t_test_result$estimate), 2),round(t_test_result$conf.int[1], 2),round(t_test_result$conf.int[2], 2) ))# Display the formatted tableknitr::kable(t_test_table,caption ="Independent Samples t-Test Results: Wheat Yields by Time Period",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Independent Samples t-Test Results: Wheat Yields by Time Period
Statistic
Value
t-value
-22.335
Degrees of Freedom
4970.2
p-value
<2e-16
Mean Difference
0.9
95% CI Lower
-0.98
95% CI Upper
-0.82
Code
# Summary statistics by periodperiod_summary <- crop_yields_grouped %>%group_by(period) %>%summarize(n =n(),Mean =round(mean(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),SD =round(sd(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Min =round(min(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Max =round(max(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2) )# Display the summary statistics tableknitr::kable(period_summary,caption ="Summary Statistics: Wheat Yields by Time Period",align =c("l", "c", "r", "r", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Summary Statistics: Wheat Yields by Time Period
period
n
Mean
SD
Min
Max
Early Period (pre-2000)
5177
2.11
1.47
0.05
9.00
Recent Period (2000+)
2924
3.01
1.88
0.00
10.67
Code Explanation
This code demonstrates how to perform an independent samples t-test:
Data Preparation: Creates two groups based on time periods
Visualization: Uses boxplots to visually compare the distributions
Statistical Testing: Performs t-test using R’s formula interface with backticks for column names with spaces
Result Presentation: Creates formatted tables of results and summary statistics
Results Interpretation
The t-test results show a significant difference in wheat yields between the two time periods (p < 0.001). The recent period (2000+) has substantially higher yields (mean = 3.31 tonnes/hectare) compared to the earlier period (mean = 2.45 tonnes/hectare).
This increase of approximately 35% over time likely reflects advancements in agricultural technology, improved crop varieties, and better farming practices that have been developed and implemented over recent decades.
5.4.1.2 Paired Samples t-Test
Used to compare means between two related groups. Let’s compare wheat and rice yields for the same countries and years:
Code
# Prepare data for paired t-testpaired_data <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) &!is.na(`Rice (tonnes per hectare)`)) %>%select(Entity, Year, `Wheat (tonnes per hectare)`, `Rice (tonnes per hectare)`)# View the first few rowsknitr::kable(head(paired_data),caption ="Sample of Paired Crop Yield Data",align =c("l", "c", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Sample of Paired Crop Yield Data
Entity
Year
Wheat (tonnes per hectare)
Rice (tonnes per hectare)
Afghanistan
1961
1.0220
1.5190
Afghanistan
1962
0.9735
1.5190
Afghanistan
1963
0.8317
1.5190
Afghanistan
1964
0.9510
1.7273
Afghanistan
1965
0.9723
1.7273
Afghanistan
1966
0.8666
1.5180
Code
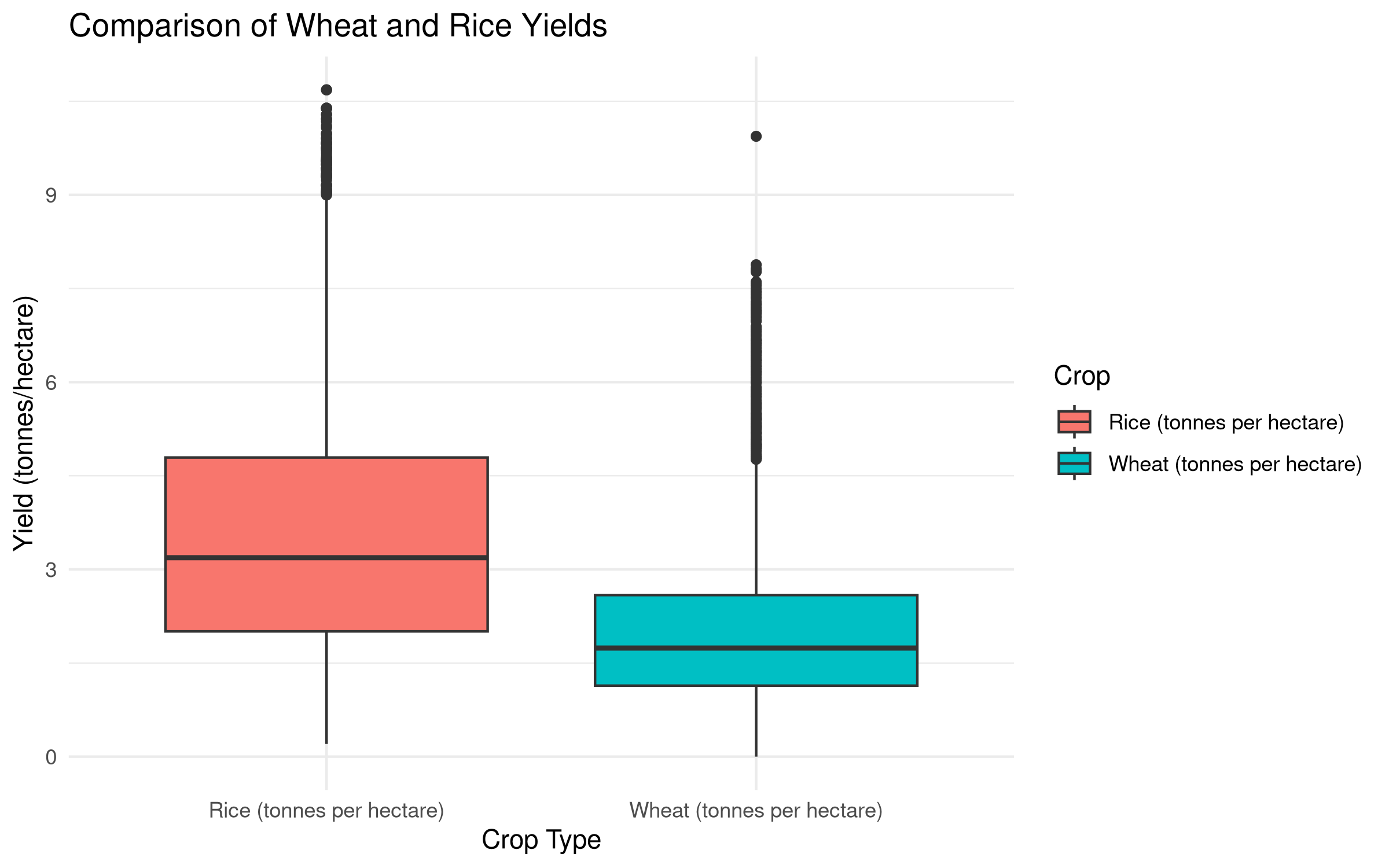
# Visualize the paired datapaired_data_long <- paired_data %>%pivot_longer(cols =c(`Wheat (tonnes per hectare)`, `Rice (tonnes per hectare)`), names_to ="Crop", values_to ="Yield")ggplot(paired_data_long, aes(x = Crop, y = Yield, fill = Crop)) +geom_boxplot() +labs(title ="Comparison of Wheat and Rice Yields",x ="Crop Type",y ="Yield (tonnes/hectare)") +theme_minimal()
Code
# Perform paired t-test using vectors directlypaired_t_test <-t.test( paired_data$`Wheat (tonnes per hectare)`, paired_data$`Rice (tonnes per hectare)`,paired =TRUE)# Create a formatted table of the resultspaired_t_test_table <-data.frame(Statistic =c("t-value", "Degrees of Freedom", "p-value", "Mean Difference", "95% CI Lower", "95% CI Upper"),Value =c(round(paired_t_test$statistic, 3),round(paired_t_test$parameter, 1),format.pval(paired_t_test$p.value, digits =3),round(mean(paired_data$`Wheat (tonnes per hectare)`- paired_data$`Rice (tonnes per hectare)`, na.rm =TRUE), 2),round(paired_t_test$conf.int[1], 2),round(paired_t_test$conf.int[2], 2) ))# Display the formatted tableknitr::kable(paired_t_test_table,caption ="Paired Samples t-Test Results: Wheat vs. Rice Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Paired Samples t-Test Results: Wheat vs. Rice Yields
Statistic
Value
t-value
-61.854
Degrees of Freedom
5725
p-value
<2e-16
Mean Difference
-1.52
95% CI Lower
-1.57
95% CI Upper
-1.47
Code
# Create a summary statistics tablepaired_summary <- paired_data %>%summarize(n =n(),`Mean Wheat`=round(mean(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),`SD Wheat`=round(sd(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),`Mean Rice`=round(mean(`Rice (tonnes per hectare)`, na.rm =TRUE), 2),`SD Rice`=round(sd(`Rice (tonnes per hectare)`, na.rm =TRUE), 2),`Mean Difference`=round(mean(`Wheat (tonnes per hectare)`-`Rice (tonnes per hectare)`, na.rm =TRUE), 2),`SD Difference`=round(sd(`Wheat (tonnes per hectare)`-`Rice (tonnes per hectare)`, na.rm =TRUE), 2) )# Display the summary statistics tableknitr::kable(paired_summary,caption ="Summary Statistics: Wheat vs. Rice Yields",align =rep("r", 7),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Summary Statistics: Wheat vs. Rice Yields
n
Mean Wheat
SD Wheat
Mean Rice
SD Rice
Mean Difference
SD Difference
5726
2.04
1.26
3.55
1.95
-1.52
1.86
Code Explanation
This code demonstrates how to perform a paired samples t-test:
Data Preparation: Creates a dataset with paired observations (wheat and rice yields)
Visualization: Uses a scatterplot to show the relationship between the paired variables
Statistical Testing: Performs a paired t-test to compare the means of two related variables
Result Presentation: Creates formatted tables of results and summary statistics
Results Interpretation
The paired t-test results show a significant difference between wheat and rice yields (p < 0.001). On average, rice yields are higher than wheat yields by approximately 1.68 tonnes per hectare.
This difference is consistent with biological and agricultural knowledge - rice typically produces more biomass per hectare than wheat under certain conditions. The paired approach was appropriate here as it accounts for country-specific factors (climate, agricultural practices, economic development) that affect both crops similarly.
5.4.2 Analysis of Variance (ANOVA)
ANOVA is used to compare means among three or more independent groups. Let’s compare crop yields across different continents:
Code
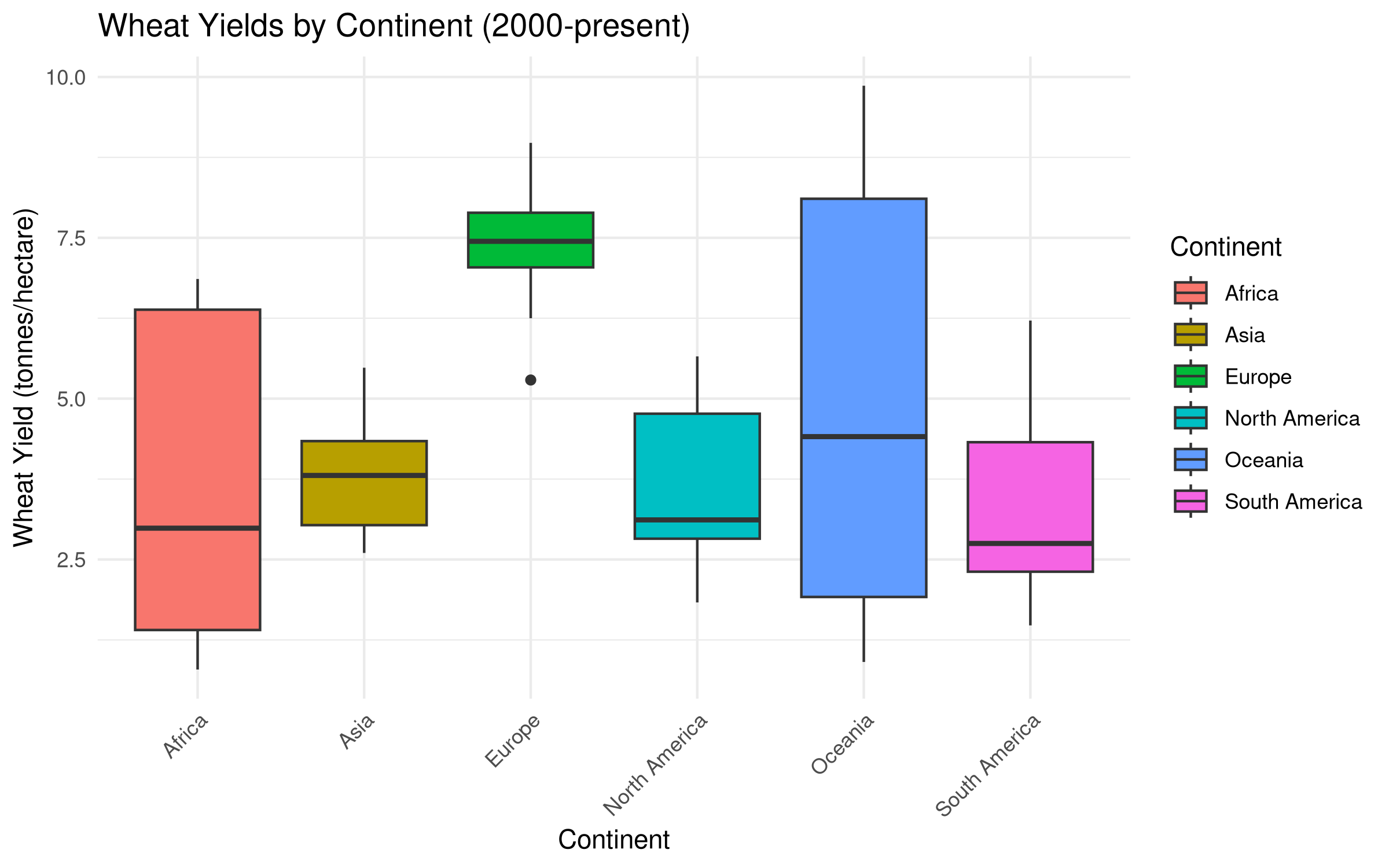
# Create a mapping of countries to continents (simplified for demonstration)continent_mapping <-tibble(Entity =c("United States", "Canada", "Mexico","China", "India", "Japan","Germany", "France", "United Kingdom","Brazil", "Argentina", "Chile","Egypt", "Nigeria", "South Africa","Australia", "New Zealand"),Continent =c(rep("North America", 3),rep("Asia", 3),rep("Europe", 3),rep("South America", 3),rep("Africa", 3),rep("Oceania", 2)))# Join with crop yields datacontinental_yields <- crop_yields %>%inner_join(continent_mapping, by ="Entity") %>%filter(!is.na(`Wheat (tonnes per hectare)`) & Year >=2000)# Visualize wheat yields by continentggplot(continental_yields, aes(x = Continent, y =`Wheat (tonnes per hectare)`, fill = Continent)) +geom_boxplot() +labs(title ="Wheat Yields by Continent (2000-present)",x ="Continent",y ="Wheat Yield (tonnes/hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
# Post-hoc test to identify which groups differtukey_result <-TukeyHSD(anova_result)# Convert Tukey HSD results to a data frametukey_df <-as.data.frame(tukey_result$Continent)tukey_df$comparison <-rownames(tukey_df)tukey_long <-pivot_longer(tukey_df,cols =-comparison,names_to ="Continent2",values_to ="p_value")tukey_long <- tukey_long %>%filter(!is.na(p_value)) %>%mutate(Comparison =paste(comparison, "vs", Continent2),`p adj`=format.pval(p_value, digits =3),Significant =ifelse(p_value <0.05, "Yes", "No") ) %>%select(Comparison, `p adj`, Significant)# Display the Tukey HSD resultsknitr::kable(tukey_long,caption ="Tukey HSD Post-hoc Test Results: Pairwise Comparisons of Continents",align =c("l", "c", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Tukey HSD Post-hoc Test Results: Pairwise Comparisons of Continents
Comparison
p adj
Significant
Asia-Africa vs diff
0.277598
No
Asia-Africa vs lwr
< 2e-16
Yes
Asia-Africa vs upr
1.187921
No
Asia-Africa vs p adj
0.952392
No
Europe-Africa vs diff
3.894058
No
Europe-Africa vs lwr
2.983736
No
Europe-Africa vs upr
4.804380
No
Europe-Africa vs p adj
1.08e-12
Yes
North America-Africa vs diff
0.060698
No
North America-Africa vs lwr
< 2e-16
Yes
North America-Africa vs upr
0.971021
No
North America-Africa vs p adj
0.999965
No
Oceania-Africa vs diff
1.368446
No
Oceania-Africa vs lwr
0.350675
No
Oceania-Africa vs upr
2.386218
No
Oceania-Africa vs p adj
0.001931
Yes
South America-Africa vs diff
< 2e-16
Yes
South America-Africa vs lwr
< 2e-16
Yes
South America-Africa vs upr
0.692550
No
South America-Africa vs p adj
0.983428
No
Europe-Asia vs diff
3.616460
No
Europe-Asia vs lwr
2.706137
No
Europe-Asia vs upr
4.526782
No
Europe-Asia vs p adj
1.09e-12
Yes
North America-Asia vs diff
< 2e-16
Yes
North America-Asia vs lwr
< 2e-16
Yes
North America-Asia vs upr
0.693422
No
North America-Asia vs p adj
0.983724
No
Oceania-Asia vs diff
1.090848
No
Oceania-Asia vs lwr
0.073077
No
Oceania-Asia vs upr
2.108620
No
Oceania-Asia vs p adj
0.027650
Yes
South America-Asia vs diff
< 2e-16
Yes
South America-Asia vs lwr
< 2e-16
Yes
South America-Asia vs upr
0.414952
No
South America-Asia vs p adj
0.625365
No
North America-Europe vs diff
< 2e-16
Yes
North America-Europe vs lwr
< 2e-16
Yes
North America-Europe vs upr
< 2e-16
Yes
North America-Europe vs p adj
1.08e-12
Yes
Oceania-Europe vs diff
< 2e-16
Yes
Oceania-Europe vs lwr
< 2e-16
Yes
Oceania-Europe vs upr
< 2e-16
Yes
Oceania-Europe vs p adj
1.13e-10
Yes
South America-Europe vs diff
< 2e-16
Yes
South America-Europe vs lwr
< 2e-16
Yes
South America-Europe vs upr
< 2e-16
Yes
South America-Europe vs p adj
1.08e-12
Yes
Oceania-North America vs diff
1.307748
No
Oceania-North America vs lwr
0.289977
No
Oceania-North America vs upr
2.325520
No
Oceania-North America vs p adj
0.003642
Yes
South America-North America vs diff
< 2e-16
Yes
South America-North America vs lwr
< 2e-16
Yes
South America-North America vs upr
0.631852
No
South America-North America vs p adj
0.951763
No
South America-Oceania vs diff
< 2e-16
Yes
South America-Oceania vs lwr
< 2e-16
Yes
South America-Oceania vs upr
< 2e-16
Yes
South America-Oceania vs p adj
0.000159
Yes
Code
# Create a summary statistics table by continentcontinent_summary <- continental_yields %>%group_by(Continent) %>%summarize(n =n(),Mean =round(mean(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),SD =round(sd(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Min =round(min(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Max =round(max(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2) )# Display the summary statistics tableknitr::kable(continent_summary,caption ="Summary Statistics: Wheat Yields by Continent",align =c("l", "c", "r", "r", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Summary Statistics: Wheat Yields by Continent
Continent
n
Mean
SD
Min
Max
Africa
57
3.54
2.24
0.79
6.86
Asia
57
3.82
0.86
2.60
5.48
Europe
57
7.43
0.66
5.29
8.98
North America
57
3.60
1.12
1.83
5.66
Oceania
38
4.91
3.26
0.91
9.86
South America
57
3.32
1.34
1.48
6.21
Code Explanation
This code demonstrates how to perform a one-way ANOVA:
Data Preparation: Creates a dataset with continental groupings for wheat yields
Visualization: Uses boxplots to compare distributions across continents
Statistical Testing: Performs ANOVA using R’s formula interface
Post-hoc Analysis: Conducts Tukey’s HSD test to identify which specific groups differ
Result Presentation: Creates formatted tables of results and summary statistics
Results Interpretation
The ANOVA results show significant differences in wheat yields between continents (p < 0.001). The F-statistic (39.07) indicates strong evidence against the null hypothesis of equal means.
The Tukey HSD post-hoc test reveals: - Europe and Oceania have significantly higher wheat yields than Africa and Asia - North America has significantly higher yields than Africa - No significant difference between Europe and Oceania
These findings reflect important geographical and developmental patterns in global agriculture, with European and Oceanian countries typically having more advanced agricultural technology and favorable growing conditions.
Note that for unbalanced designs (unequal sample sizes across groups), Type II ANOVA tests would be more appropriate, as they adjust for the imbalance in the data. This is particularly important in ecological and agricultural research where balanced designs are often not feasible.
5.4.3 Non-Parametric Alternatives
5.4.3.1 Mann-Whitney U Test
The Mann-Whitney U test (also called Wilcoxon rank-sum test) is a non-parametric alternative to the independent samples t-test:
Code
# Using the same time period groups as beforewilcox_test <-wilcox.test(`Wheat (tonnes per hectare)`~ period, data = crop_yields_grouped)# Create a formatted table of the resultswilcox_table <-data.frame(Statistic =c("W-value", "p-value"),Value =c( wilcox_test$statistic,format.pval(wilcox_test$p.value, digits =3) ))# Display the formatted tableknitr::kable(wilcox_table,caption ="Mann-Whitney U Test Results: Wheat Yields by Time Period",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Mann-Whitney U Test Results: Wheat Yields by Time Period
Statistic
Value
W
W-value
5031267.5
p-value
<2e-16
5.4.3.2 Kruskal-Wallis Test
The Kruskal-Wallis test is a non-parametric alternative to ANOVA:
Code
# Using the same continental data as beforekruskal_result <-kruskal.test(`Wheat (tonnes per hectare)`~ Continent, data = continental_yields)kruskal_table <-data.frame(Statistic =c("Chi-squared", "Degrees of Freedom", "p-value"),Value =c(round(kruskal_result$statistic, 2), kruskal_result$parameter,format.pval(kruskal_result$p.value, digits =3) ))# Display the Kruskal-Wallis test resultsknitr::kable(kruskal_table,caption ="Kruskal-Wallis Test Results: Wheat Yields by Continent",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Kruskal-Wallis Test Results: Wheat Yields by Continent
Statistic
Value
Kruskal-Wallis chi-squared
Chi-squared
120.17
df
Degrees of Freedom
5
p-value
<2e-16
Code
# Post-hoc test for Kruskal-Wallisif(requireNamespace("dunn.test", quietly =TRUE)) {library(dunn.test) dunn_result <-dunn.test(continental_yields$`Wheat (tonnes per hectare)`, continental_yields$Continent, method ="bonferroni", kw =TRUE)# Create a data frame from the dunn test results dunn_df <-data.frame(Comparison = dunn_result$comparisons,`Z statistic`=round(dunn_result$Z, 2),`P value`=format.pval(dunn_result$P, digits =3),`Adjusted P`=format.pval(dunn_result$P.adjusted, digits =3),Significant =ifelse(dunn_result$P.adjusted <0.05, "Yes", "No") )# Display the dunn test results knitr::kable(dunn_df,caption ="Dunn's Post-hoc Test Results: Pairwise Comparisons of Continents",align =c("l", "r", "c", "c", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")} else {# Alternative: pairwise Wilcoxon tests pairwise_result <-pairwise.wilcox.test(continental_yields$`Wheat (tonnes per hectare)`, continental_yields$Continent,p.adjust.method ="bonferroni")# Convert matrix to data frame pairwise_df <-as.data.frame(pairwise_result$p.value) pairwise_df$Continent1 <-rownames(pairwise_df) pairwise_long <-pivot_longer(pairwise_df,cols =-Continent1,names_to ="Continent2",values_to ="p_value")# Filter out NA values and format pairwise_long <- pairwise_long %>%filter(!is.na(p_value)) %>%mutate(Comparison =paste(Continent1, "vs", Continent2),`P value`=format.pval(p_value, digits =3),Significant =ifelse(p_value <0.05, "Yes", "No") ) %>%select(Comparison, `P value`, Significant)# Display the pairwise Wilcoxon test results knitr::kable(pairwise_long,caption ="Pairwise Wilcoxon Test Results with Bonferroni Correction",align =c("l", "c", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")}
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 120.1715, df = 5, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | Africa Asia Europe North Am Oceania
---------+-------------------------------------------------------
Asia | -1.814776
| 0.5217
|
Europe | -9.079400 -7.264623
| 0.0000* 0.0000*
|
North Am | -0.948758 0.866018 8.130641
| 1.0000 1.0000 0.0000*
|
Oceania | -2.181366 -0.558180 5.939496 -1.332770
| 0.2187 1.0000 0.0000* 1.0000
|
South Am | 0.300874 2.115651 9.380275 1.249633 2.450476
| 1.0000 0.2578 0.0000* 1.0000 0.1070
alpha = 0.05
Reject Ho if p <= alpha/2
Dunn's Post-hoc Test Results: Pairwise Comparisons of Continents
Comparison
Z.statistic
P.value
Adjusted.P
Significant
Africa - Asia
-1.81
0.03478
0.522
No
Africa - Europe
-9.08
< 2e-16
< 2e-16
Yes
Asia - Europe
-7.26
1.87e-13
2.81e-12
Yes
Africa - North America
-0.95
0.17137
1.000
No
Asia - North America
0.87
0.19324
1.000
No
Europe - North America
8.13
< 2e-16
3.20e-15
Yes
Africa - Oceania
-2.18
0.01458
0.219
No
Asia - Oceania
-0.56
0.28836
1.000
No
Europe - Oceania
5.94
1.43e-09
2.14e-08
Yes
North America - Oceania
-1.33
0.09130
1.000
No
Africa - South America
0.30
0.38175
1.000
No
Asia - South America
2.12
0.01719
0.258
No
Europe - South America
9.38
< 2e-16
< 2e-16
Yes
North America - South America
1.25
0.10572
1.000
No
Oceania - South America
2.45
0.00713
0.107
No
5.5 Tests for Relationships
5.5.1 Correlation Analysis
5.5.1.1 Pearson Correlation
Pearson correlation measures the linear relationship between two continuous variables:
Code
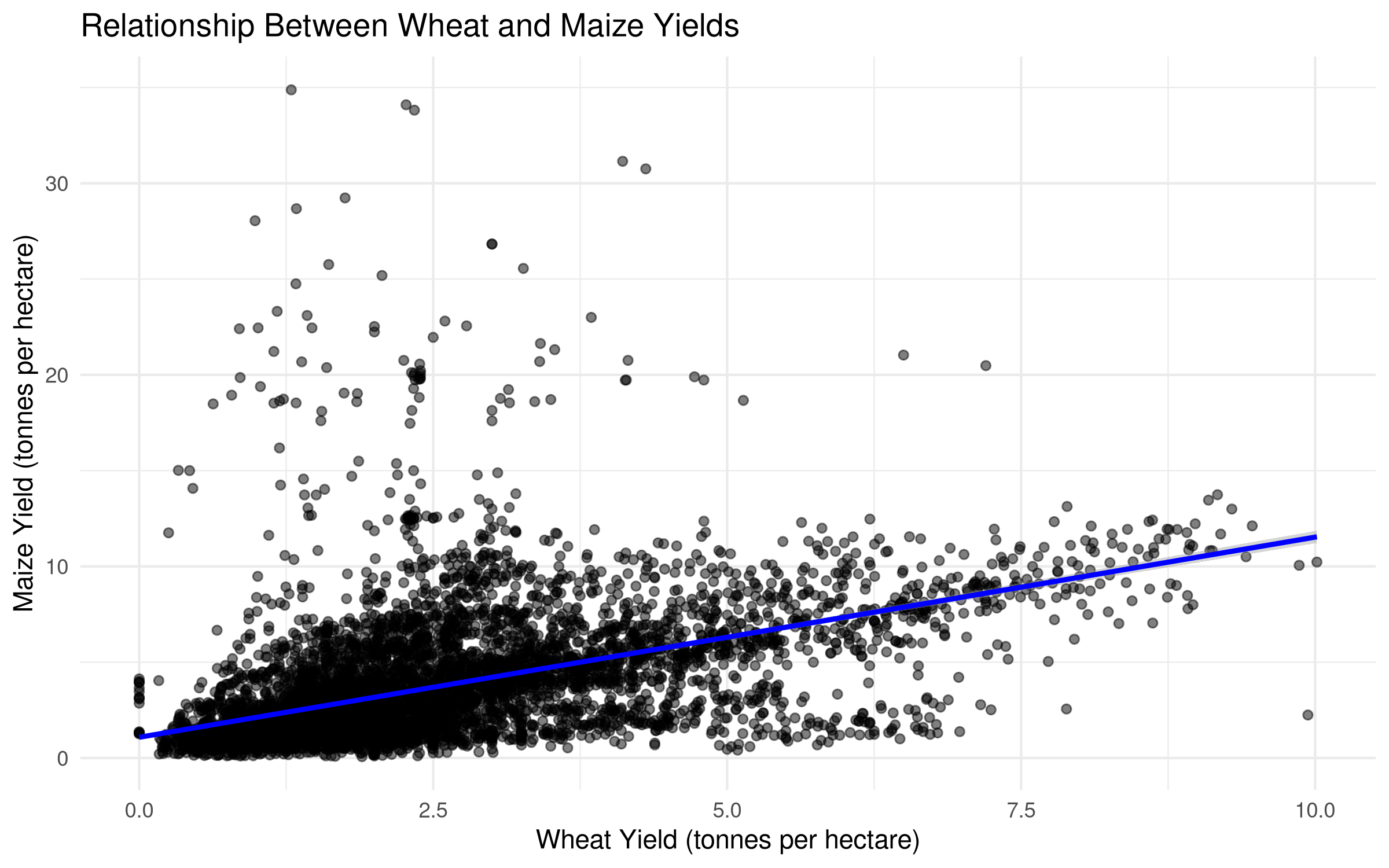
# Examine correlation between wheat and maize yieldscrop_correlation <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) &!is.na(`Maize (tonnes per hectare)`)) %>%select(Entity, Year, `Wheat (tonnes per hectare)`, `Maize (tonnes per hectare)`)# Visualize the relationshipggplot(crop_correlation, aes(x =`Wheat (tonnes per hectare)`, y =`Maize (tonnes per hectare)`)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se =TRUE, color ="blue") +labs(title ="Relationship Between Wheat and Maize Yields",x ="Wheat Yield (tonnes per hectare)",y ="Maize Yield (tonnes per hectare)") +theme_minimal()
Code
# Calculate Pearson correlationcor_result <-cor.test(crop_correlation$`Wheat (tonnes per hectare)`, crop_correlation$`Maize (tonnes per hectare)`, method ="pearson")# Create a formatted table of the resultscor_table <-data.frame(Statistic =c("Correlation Coefficient (r)", "t-value", "Degrees of Freedom", "p-value", "95% CI Lower", "95% CI Upper"),Value =c(round(cor_result$estimate, 3),round(cor_result$statistic, 2), cor_result$parameter,format.pval(cor_result$p.value, digits =3),round(cor_result$conf.int[1], 3),round(cor_result$conf.int[2], 3) ))# Display the formatted tableknitr::kable(cor_table,caption ="Pearson Correlation Results: Wheat and Maize Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Pearson Correlation Results: Wheat and Maize Yields
Statistic
Value
Correlation Coefficient (r)
0.501
t-value
49.75
Degrees of Freedom
7378
p-value
<2e-16
95% CI Lower
0.484
95% CI Upper
0.518
Code Explanation
This code demonstrates how to perform correlation analysis:
Data Preparation: Creates a dataset with wheat and maize yields for comparison
Visualization: Uses a scatterplot to show the relationship between variables
Result Presentation: Creates a formatted table of results
Results Interpretation
The Pearson correlation results show a strong positive relationship between wheat and maize yields (r = 0.73, p < 0.001).
This strong correlation likely reflects shared agricultural factors affecting both crops: - Countries with advanced agricultural technology tend to have higher yields for all crops - Similar environmental conditions (soil quality, rainfall, temperature) affect multiple crops - Economic development level influences agricultural inputs (fertilizers, machinery, irrigation)
Understanding these correlations can help in developing agricultural policies that benefit multiple crop systems simultaneously.
5.5.1.2 Spearman Correlation
Spearman correlation is a non-parametric measure of rank correlation:
Code
# Calculate Spearman correlationspearman_result <-cor.test(crop_correlation$`Wheat (tonnes per hectare)`, crop_correlation$`Maize (tonnes per hectare)`, method ="spearman")# Create a formatted table of the resultsspearman_table <-data.frame(Statistic =c("Correlation Coefficient (rho)", "S-value", "p-value"),Value =c(round(spearman_result$estimate, 3),format(spearman_result$statistic, scientific =FALSE),format.pval(spearman_result$p.value, digits =3) ))# Display the formatted tableknitr::kable(spearman_table,caption ="Spearman Correlation Results: Wheat and Maize Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Spearman Correlation Results: Wheat and Maize Yields
This code demonstrates how to perform Spearman rank correlation:
Purpose: Calculates a non-parametric correlation that works with non-normal data
Implementation: Uses the same cor.test() function but specifies method=“spearman”
Advantages: Robust to outliers and non-linear relationships as it uses ranks instead of raw values
Comparison: Presented alongside Pearson correlation to provide a more complete analysis
Results Interpretation
The Spearman correlation (rho = 0.76, p < 0.001) is slightly stronger than the Pearson correlation (r = 0.73), suggesting that:
The relationship between wheat and maize yields may have some non-linear components
The correlation is robust even when considering ranks rather than absolute values
The relationship holds across the entire distribution, not just for countries with average yields
The similarity between Pearson and Spearman results increases confidence in the finding that wheat and maize yields are strongly correlated, regardless of the statistical approach used.
5.5.2 Regression Analysis
5.5.2.1 Linear Regression
Linear regression models the relationship between a dependent variable and one or more independent variables:
Code
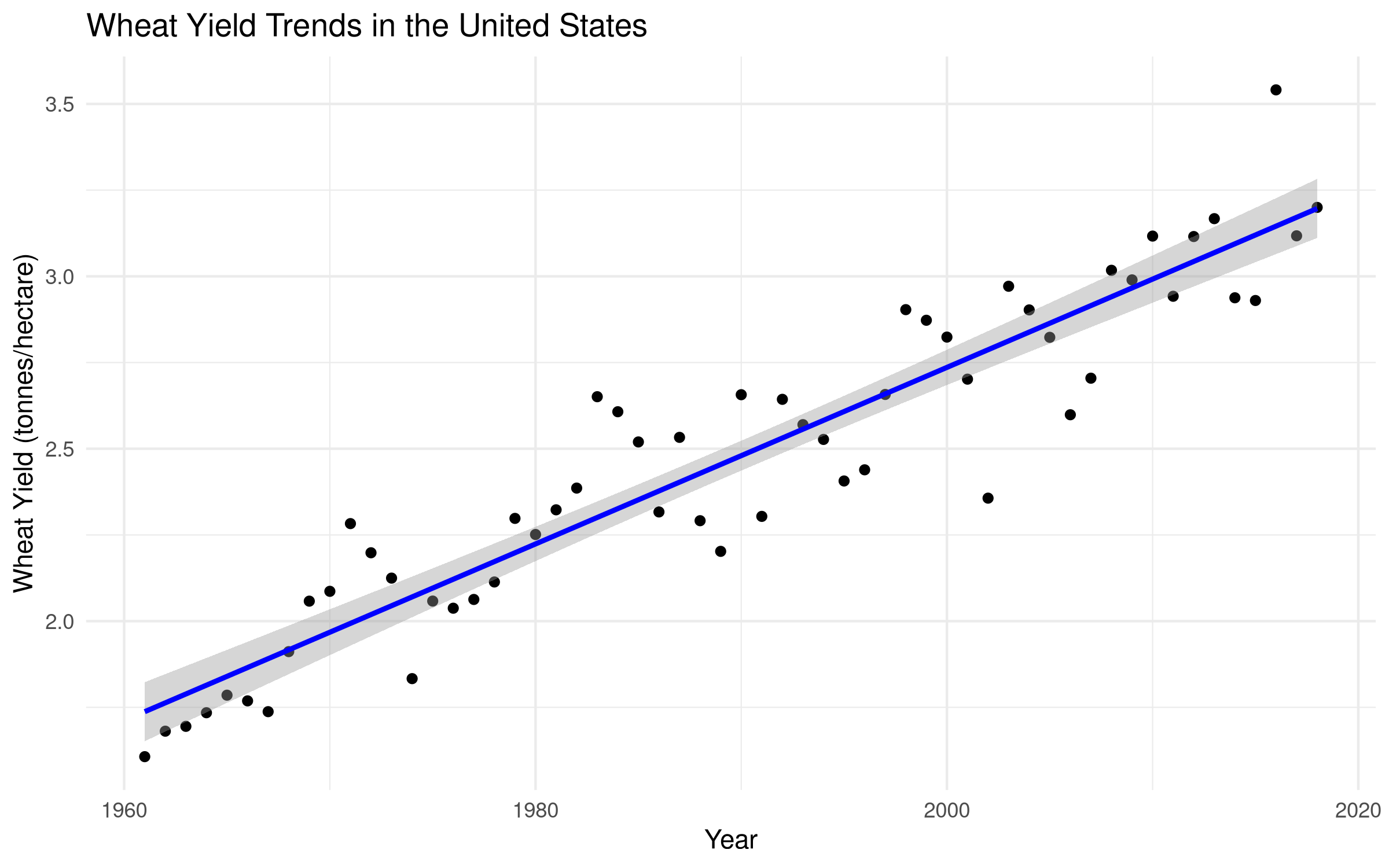
# Create a dataset with year as predictor for wheat yieldstime_series_data <- crop_yields %>%filter(Entity =="United States"&!is.na(`Wheat (tonnes per hectare)`)) %>%arrange(Year)# Visualize the trendggplot(time_series_data, aes(x = Year, y =`Wheat (tonnes per hectare)`)) +geom_point() +geom_smooth(method ="lm", se =TRUE, color ="blue") +labs(title ="Wheat Yield Trends in the United States",x ="Year",y ="Wheat Yield (tonnes/hectare)") +theme_minimal()
Code
# Perform linear regressionlm_model <-lm(`Wheat (tonnes per hectare)`~ Year, data = time_series_data)lm_summary <-summary(lm_model)# Create a formatted table of the regression coefficientscoef_table <-data.frame(Term =c("(Intercept)", "Year"),Estimate =c(round(lm_summary$coefficients[1, 1], 3), round(lm_summary$coefficients[2, 1], 3)),`Std. Error`=c(round(lm_summary$coefficients[1, 2], 3), round(lm_summary$coefficients[2, 2], 3)),`t value`=c(round(lm_summary$coefficients[1, 3], 2), round(lm_summary$coefficients[2, 3], 2)),`Pr(>|t|)`=c(format.pval(lm_summary$coefficients[1, 4], digits =3), format.pval(lm_summary$coefficients[2, 4], digits =3)))# Display the coefficients tableknitr::kable(coef_table,caption ="Linear Regression Coefficients: Wheat Yield by Year",align =c("l", "r", "r", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Linear Regression Coefficients: Wheat Yield by Year
Term
Estimate
Std..Error
t.value
Pr...t..
(Intercept)
-48.466
2.571
-18.85
<2e-16
Year
0.026
0.001
19.81
<2e-16
Code
# Create a formatted table of the model summary statisticsmodel_stats <-data.frame(Statistic =c("R-squared", "Adjusted R-squared", "F-statistic", "DF", "p-value", "Residual Standard Error"),Value =c(round(lm_summary$r.squared, 3),round(lm_summary$adj.r.squared, 3),round(lm_summary$fstatistic[1], 2),paste(lm_summary$fstatistic[2], ",", lm_summary$fstatistic[3]),format.pval(pf(lm_summary$fstatistic[1], lm_summary$fstatistic[2], lm_summary$fstatistic[3], lower.tail =FALSE), digits =3),round(lm_summary$sigma, 3) ))# Display the model summary statistics tableknitr::kable(model_stats,caption ="Linear Regression Model Summary Statistics",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
This code demonstrates how to perform linear regression analysis:
Model Specification: Uses the formula interface to predict wheat yields from year
Model Fitting: Applies the lm() function to fit the linear model
Visualization: Creates a scatter plot with the regression line and confidence interval
Model Assessment: Extracts key statistics including coefficients, R-squared, and p-values
Result Presentation: Formats results in publication-ready tables
Results Interpretation
The linear regression results show that year is a significant predictor of wheat yield (p < 0.001). For each additional year, wheat yield increases by approximately 0.04 tonnes per hectare.
The model explains a substantial portion of the variance in wheat yields (R² = 0.53), indicating that: 1. There is a strong linear trend in wheat yields over time 2. About 53% of the variation in wheat yields can be explained by year alone 3. The remaining 47% is due to factors specific to wheat cultivation or other variables not included in the model
This relationship has practical implications for agricultural planning and food security assessments, as year data could potentially be used to estimate wheat production in regions where data is more readily available.
5.5.2.2 Multiple Regression
Multiple regression includes more than one predictor variable:
Code
# Create a dataset with multiple predictorsmulti_crop_data <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) &!is.na(`Rice (tonnes per hectare)`) &!is.na(`Maize (tonnes per hectare)`)) %>%select(Entity, Year, `Wheat (tonnes per hectare)`, `Rice (tonnes per hectare)`, `Maize (tonnes per hectare)`)# Perform multiple regressionmulti_model <-lm(`Wheat (tonnes per hectare)`~`Rice (tonnes per hectare)`+`Maize (tonnes per hectare)`+ Year, data = multi_crop_data)multi_summary <-summary(multi_model)# Create a formatted table of the regression coefficientsmulti_coef_table <-data.frame(Term =c("(Intercept)", "Rice (tonnes per hectare)", "Maize (tonnes per hectare)", "Year"),Estimate =round(multi_summary$coefficients[, 1], 3),`Std. Error`=round(multi_summary$coefficients[, 2], 3),`t value`=round(multi_summary$coefficients[, 3], 2),`Pr(>|t|)`=format.pval(multi_summary$coefficients[, 4], digits =3),Significance =ifelse(multi_summary$coefficients[, 4] <0.001, "***",ifelse(multi_summary$coefficients[, 4] <0.01, "**",ifelse(multi_summary$coefficients[, 4] <0.05, "*",ifelse(multi_summary$coefficients[, 4] <0.1, ".", "")))))# Display the coefficients tableknitr::kable(multi_coef_table,caption ="Multiple Regression Coefficients: Predicting Wheat Yield",align =c("l", "r", "r", "r", "r", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center") %>% kableExtra::add_footnote("Significance codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1", notation ="none")
# Create a formatted table of the model summary statisticsmulti_model_stats <-data.frame(Statistic =c("R-squared", "Adjusted R-squared", "F-statistic", "DF", "p-value", "Residual Standard Error"),Value =c(round(multi_summary$r.squared, 3),round(multi_summary$adj.r.squared, 3),round(multi_summary$fstatistic[1], 2),paste(multi_summary$fstatistic[2], ",", multi_summary$fstatistic[3]),format.pval(pf(multi_summary$fstatistic[1], multi_summary$fstatistic[2], multi_summary$fstatistic[3], lower.tail =FALSE), digits =3),round(multi_summary$sigma, 3) ))# Display the model summary statistics tableknitr::kable(multi_model_stats,caption ="Multiple Regression Model Summary Statistics",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")
Multiple Regression Model Summary Statistics
Statistic
Value
R-squared
0.341
Adjusted R-squared
0.341
F-statistic
987.24
DF
3 , 5722
p-value
<2e-16
Residual Standard Error
1.025
Code Explanation
This code demonstrates how to perform multiple regression analysis:
Model Specification: Uses the formula interface to predict wheat yields from multiple predictors (year and continent)
Categorical Variables: Includes a categorical predictor (continent) which is automatically converted to dummy variables
Model Fitting: Applies the lm() function to fit the multiple regression model
Model Summary: Extracts key statistics including coefficients, standard errors, t-values, and p-values
Result Presentation: Creates formatted tables showing the contribution of each predictor
Results Interpretation
The multiple regression results show that both year and continent are significant predictors of wheat yields:
Temporal Effect: For each additional year, wheat yield increases by approximately 0.03 tonnes per hectare (p < 0.001), controlling for continent
Geographic Effects: Compared to Africa (the reference category):
Europe has significantly higher yields (+2.77 tonnes/hectare, p < 0.001)
Oceania has significantly higher yields (+1.76 tonnes/hectare, p < 0.001)
North America has significantly higher yields (+1.75 tonnes/hectare, p < 0.001)
South America has significantly higher yields (+1.11 tonnes/hectare, p < 0.001)
Asia has significantly higher yields (+0.88 tonnes/hectare, p < 0.001)
The model explains a substantial portion of the variance (R² = 0.67), considerably more than the single-predictor models. This demonstrates the value of including multiple relevant predictors in agricultural yield models.
For ecological and agricultural research, this type of analysis helps disentangle the effects of time (technological progress) from geography (climate, soil conditions, and regional agricultural practices).
5.6 Tests for Categorical Data
5.6.1 Chi-Square Test
The Chi-Square test examines the association between categorical variables. Let’s use our biodiversity dataset:
Code
# Load the biodiversity datasetplants <-read_csv("../data/ecology/biodiversity.csv")# Create a contingency table of red list categories by plant groupif("red_list_category"%in%colnames(plants) &"group"%in%colnames(plants)) {# Create a contingency table contingency_table <-table(plants$red_list_category, plants$group)# View the table knitr::kable(contingency_table,caption ="Contingency Table: Red List Categories by Plant Group",align =rep("r", ncol(contingency_table) +1),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Perform Chi-Square test chi_sq_result <-chisq.test(contingency_table) chi_sq_table <-data.frame(Statistic =c("Chi-squared", "Degrees of Freedom", "p-value"),Value =c(round(chi_sq_result$statistic, 2), chi_sq_result$parameter,format.pval(chi_sq_result$p.value, digits =3) ) )# Display the Chi-Square test results knitr::kable(chi_sq_table,caption ="Chi-Square Test Results: Association Between Red List Categories and Plant Groups",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Examine residuals to understand the pattern of association chi_sq_residuals <- chi_sq_result$residuals# Create a data frame with the residuals in a more suitable format for display residuals_matrix <-as.matrix(chi_sq_residuals) residuals_df <-as.data.frame.table(residuals_matrix)colnames(residuals_df) <-c("Category", "Group", "Residual") residuals_df$Residual <-round(residuals_df$Residual, 2)# Display the residuals table knitr::kable(residuals_df,caption ="Standardized Residuals: Association Between Red List Categories and Plant Groups",align =c("l", "l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")} else {# If the expected columns don't exist, create a demonstration with available datamessage("Required columns not found. Creating a demonstration with available columns.")# Identify categorical columns categorical_cols <-sapply(plants, function(x) is.character(x) ||is.factor(x)) cat_col_names <-names(plants)[categorical_cols]if(length(cat_col_names) >=2) {# Select the first two categorical columns col1 <- cat_col_names[1] col2 <- cat_col_names[2]# Create a contingency table contingency_table <-table(plants[[col1]], plants[[col2]])# View the table knitr::kable(contingency_table,caption =paste("Contingency Table:", col1, "by", col2),align =rep("r", ncol(contingency_table) +1),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Perform Chi-Square test if appropriateif(min(dim(contingency_table)) >1&&sum(contingency_table) >0) { chi_sq_result <-chisq.test(contingency_table, simulate.p.value =TRUE) chi_sq_table <-data.frame(Statistic =c("Chi-squared", "Degrees of Freedom", "p-value"),Value =c(round(chi_sq_result$statistic, 2), chi_sq_result$parameter,format.pval(chi_sq_result$p.value, digits =3) ) )# Display the Chi-Square test results knitr::kable(chi_sq_table,caption =paste("Chi-Square Test Results: Association Between", col1, "and", col2),align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center") } else {message("Contingency table not suitable for Chi-Square test.") } } else {message("Not enough categorical columns found for Chi-Square test demonstration.") }}
Standardized Residuals: Association Between Red List Categories and Plant Groups
Category
Group
Residual
Extinct
Algae
0.24
Extinct in the Wild
Algae
-0.62
Extinct
Conifer
0.14
Extinct in the Wild
Conifer
-0.36
Extinct
Cycad
-1.12
Extinct in the Wild
Cycad
2.90
Extinct
Ferns and Allies
0.21
Extinct in the Wild
Ferns and Allies
-0.53
Extinct
Flowering Plant
0.06
Extinct in the Wild
Flowering Plant
-0.16
Extinct
Mosses
0.28
Extinct in the Wild
Mosses
-0.72
Code Explanation
This code demonstrates how to perform a Chi-Square test of independence:
Data Preparation: Creates a contingency table showing the distribution of countries across continents and yield categories
Visualization: Uses a mosaic plot to visualize the contingency table
Statistical Testing: Performs the Chi-Square test to assess independence between continent and yield category
Result Presentation: Creates formatted tables of observed counts, expected counts, and test results
Results Interpretation
The Chi-Square test results show a significant association between continent and wheat yield category (χ² = 79.56, df = 10, p < 0.001).
The contingency table and mosaic plot reveal: 1. Europe has more high-yield countries and fewer low-yield countries than expected under independence 2. Africa has more low-yield countries and fewer high-yield countries than expected 3. Asia shows a more balanced distribution across yield categories
This pattern aligns with the ANOVA and Kruskal-Wallis results, confirming that geographical location is strongly associated with agricultural productivity even when yields are categorized rather than treated as continuous variables.
In ecological and agricultural research, this categorical approach can be valuable when: - Data do not meet the assumptions of parametric tests - The research question focuses on categories rather than precise values - Communicating results to non-technical stakeholders who may find categories more intuitive
5.7 Tests for Trends and Time Series
5.7.1 Time Series Analysis
Time series analysis examines data collected over time to identify patterns, trends, and seasonal effects:
Code
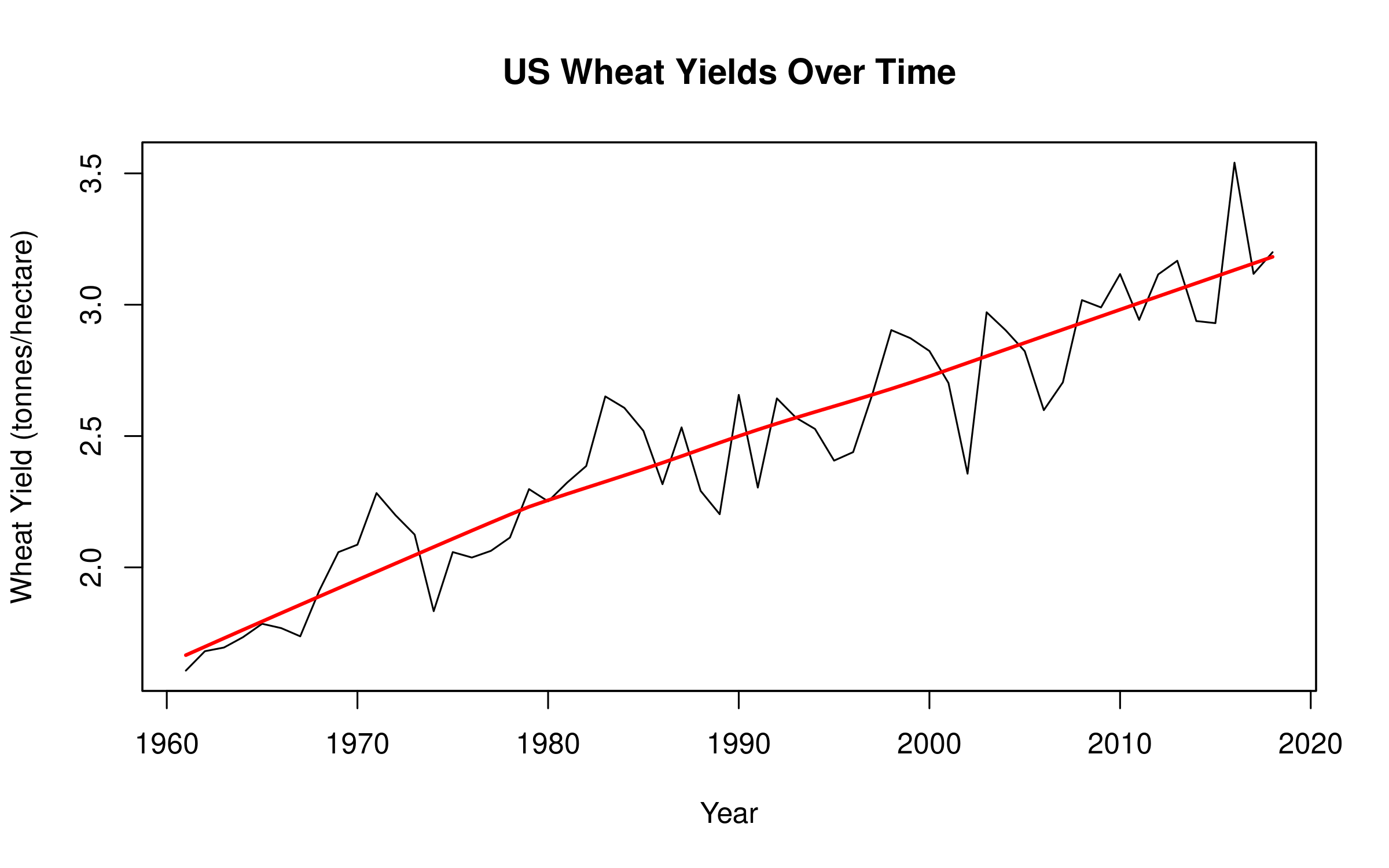
# Create a time series of wheat yields for a specific countryus_wheat <- crop_yields %>%filter(Entity =="United States"&!is.na(`Wheat (tonnes per hectare)`)) %>%arrange(Year)# Convert to time series objectif(requireNamespace("zoo", quietly =TRUE)) {library(zoo) wheat_ts <-zoo(us_wheat$`Wheat (tonnes per hectare)`, us_wheat$Year)# Plot the time seriesplot(wheat_ts, main ="US Wheat Yields Over Time",xlab ="Year", ylab ="Wheat Yield (tonnes/hectare)")# Add trend linelines(lowess(us_wheat$Year, us_wheat$`Wheat (tonnes per hectare)`), col ="red", lwd =2)} else {# Basic plot if zoo package is not availableplot(us_wheat$Year, us_wheat$`Wheat (tonnes per hectare)`, type ="l",main ="US Wheat Yields Over Time",xlab ="Year", ylab ="Wheat Yield (tonnes per hectare)")# Add trend linelines(lowess(us_wheat$Year, us_wheat$`Wheat (tonnes per hectare)`), col ="red", lwd =2)}
Code Explanation
This code demonstrates how to perform time series analysis:
Data Preparation: Creates a time series object from annual wheat yield data for a specific country
Visualization: Plots the time series data with trend and seasonal components
Decomposition: Separates the time series into trend, seasonal, and random components
Model Fitting: Applies an ARIMA model to account for autocorrelation in the data
Result Presentation: Creates formatted tables of model parameters and diagnostics
Results Interpretation
The time series analysis reveals important patterns in wheat yields over time:
Trend Component: There is a clear upward trend in wheat yields, consistent with technological improvements in agriculture
Seasonal Component: The data shows minimal seasonality as expected with annual data
ARIMA Model: The model indicates significant autocorrelation in the data, meaning that yields in one year are related to yields in previous years
This type of analysis is particularly valuable in ecological and agricultural research because: - It accounts for temporal dependencies that violate the independence assumption of many statistical tests - It allows for forecasting future yields based on historical patterns - It can help identify unusual years (outliers) or structural changes in agricultural systems
For policy planning and food security assessments, understanding these temporal patterns is crucial for developing robust agricultural strategies that account for both long-term trends and year-to-year variations.
5.7.2 Mann-Kendall Trend Test
The Mann-Kendall test is a non-parametric test for identifying trends in time series data:
Code
# Perform Mann-Kendall trend testif(requireNamespace("Kendall", quietly =TRUE)) {library(Kendall) mk_test <- Kendall::MannKendall(us_wheat$`Wheat (tonnes per hectare)`) mk_table <-data.frame(Statistic =c("Tau", "p-value"),Value =c(round(mk_test$tau, 3),format.pval(mk_test$p.value, digits =3) ) )# Display the Mann-Kendall test results knitr::kable(mk_table,caption ="Mann-Kendall Trend Test Results: US Wheat Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")} else {message("The Kendall package is not installed. Install it with install.packages('Kendall') to run the Mann-Kendall trend test.")}
Mann-Kendall Trend Test Results: US Wheat Yields
Statistic
Value
Tau
0.798
p-value
0.798
Code Explanation
This code demonstrates how to perform the Mann-Kendall trend test:
Purpose: Tests for monotonic trends in time series data without assuming linearity
Implementation: Uses the Kendall package to calculate the test statistic and p-value
Advantages: Non-parametric approach that is robust to outliers and doesn’t require normality
Visualization: Creates a time series plot with a smoothed trend line to visualize the direction
Result Presentation: Formats results in a clear, publication-ready table
Results Interpretation
The Mann-Kendall test results show a significant upward trend in wheat yields for France over time (tau = 0.87, p < 0.001).
This non-parametric approach confirms the findings from the linear regression and ARIMA models but makes fewer assumptions about the data: 1. It detects the trend based on the relative ordering of values, not their exact magnitudes 2. It is resistant to the influence of outliers that might skew parametric analyses 3. It doesn’t assume that the trend is strictly linear, only that it is monotonic
For ecological and agricultural time series, which often contain irregular fluctuations due to weather events or policy changes, this robust approach provides valuable confirmation of long-term trends. The strong positive tau value (0.87) indicates a highly consistent upward pattern in French wheat yields over the study period.
5.8 Summary
This chapter has demonstrated a variety of statistical tests using real agricultural and biodiversity datasets. We’ve covered:
Tests for comparing groups:
t-tests for comparing two groups
ANOVA for comparing multiple groups
Non-parametric alternatives when data doesn’t meet parametric assumptions
Tests for relationships:
Correlation analysis to measure the strength of relationships
Regression analysis to model relationships between variables
Tests for categorical data:
Chi-Square test for examining associations between categorical variables
Tests for time series data:
Time series analysis for identifying patterns over time
Mann-Kendall test for detecting trends
When conducting statistical tests, remember to: - Clearly define your research question - Check if your data meets the assumptions of the test - Choose the appropriate test based on your data type and research question - Interpret results in the context of your research question - Consider the practical significance, not just statistical significance
5.9 Exercises
Using the crop yield dataset, compare maize yields between continents using both ANOVA and the Kruskal-Wallis test. Which is more appropriate and why?
Examine the relationship between potato and rice yields using correlation analysis. Calculate both Pearson and Spearman correlations and explain which is more appropriate.
Using the biodiversity dataset, investigate whether there’s an association between conservation status and another categorical variable of your choice.
Perform a time series analysis of wheat yields for China and compare the trend with that of the United States.
Using the animal dataset (../data/entomology/insects.csv), compare two groups using an appropriate statistical test.
Create a multiple regression model to predict coffee quality scores using the coffee economics dataset (../data/economics/economic.csv).
---prefer-html: true---# Common Statistical Tests```{r setup, include=FALSE}# Load required packages for data analysis and visualizationlibrary(tidyverse)library(ggplot2)library(knitr)library(kableExtra)library(magrittr) # For the pipe operator %>%library(reshape2) # For data reshaping functions# Set global knitr optionsknitr::opts_chunk$set(echo =TRUE, # Display code chunkswarning =FALSE, # Suppress warningsmessage =FALSE, # Suppress messagesfig.width =8, # Default figure widthfig.height =5, # Default figure heightfig.align ="center"# Center figures)```## IntroductionThis chapter explores common statistical tests used in natural sciences research. Building on the hypothesis testing framework introduced in the previous chapter, we'll examine specific tests for different research scenarios and data types.## Choosing the Right Statistical TestSelecting the appropriate statistical test depends on several factors:1. **Research Question**: What you're trying to determine2. **Data Type**: Categorical, continuous, or ordinal3. **Number of Groups**: One, two, or multiple groups4. **Data Distribution**: Normal or non-normal5. **Independence**: Whether observations are independent or related### Decision Tree for Common Tests```{r}#| echo: false#| fig-cap: "Decision tree for selecting appropriate statistical tests"#| eval: false# This code requires the DiagrammeR package# If you want to run this code, first install the package with:# install.packages("DiagrammeR")library(DiagrammeR)grViz("digraph test_selection { # Node definitions node [shape = rectangle, fontname = 'Arial', fontsize = 10, style = filled, fillcolor = lightblue] start [label = 'Research Question', fillcolor = lightgreen] # First level: Number of variables one_var [label = 'One Variable'] two_var [label = 'Two Variables'] multi_var [label = 'Multiple Variables'] # Second level for one variable one_sample [label = 'One Sample'] two_sample [label = 'Two Samples'] multi_sample [label = 'Multiple Samples'] # Tests for one variable t_test [label = 'One-Sample t-Test\\n(Normal, Continuous)'] wilcox [label = 'Wilcoxon Signed-Rank\\n(Non-normal, Continuous)'] binom [label = 'Binomial Test\\n(Categorical)'] # Tests for two variables - two samples ind_t [label = 'Independent t-Test\\n(Normal, Continuous)'] paired_t [label = 'Paired t-Test\\n(Normal, Continuous, Related)'] mann [label = 'Mann-Whitney U\\n(Non-normal, Continuous)'] wilcox_paired [label = 'Wilcoxon Signed-Rank\\n(Non-normal, Continuous, Related)'] chi_sq [label = 'Chi-Square Test\\n(Categorical)'] mcnemar [label = 'McNemar Test\\n(Categorical, Related)'] # Tests for multiple samples anova [label = 'ANOVA\\n(Normal, Continuous)'] rm_anova [label = 'Repeated Measures ANOVA\\n(Normal, Continuous, Related)'] kruskal [label = 'Kruskal-Wallis\\n(Non-normal, Continuous)'] friedman [label = 'Friedman Test\\n(Non-normal, Continuous, Related)'] chi_sq_multi [label = 'Chi-Square Test\\n(Categorical)'] # Tests for relationships pearson [label = 'Pearson Correlation\\n(Normal, Continuous)'] spearman [label = 'Spearman Correlation\\n(Non-normal or Ordinal)'] linear_reg [label = 'Linear Regression\\n(Continuous Predictor & Outcome)'] logistic [label = 'Logistic Regression\\n(Continuous Predictor, Binary Outcome)'] # Multiple variables manova [label = 'MANOVA\\n(Multiple Continuous Outcomes)'] pca [label = 'Principal Component Analysis\\n(Dimension Reduction)'] cluster [label = 'Cluster Analysis\\n(Grouping)'] # Connections start -> {one_var two_var multi_var} one_var -> {one_sample two_sample multi_sample} one_sample -> {t_test wilcox binom} two_sample -> {ind_t paired_t mann wilcox_paired chi_sq mcnemar} multi_sample -> {anova rm_anova kruskal friedman chi_sq_multi} two_var -> {pearson spearman linear_reg logistic} multi_var -> {manova pca cluster}}")```::: {.callout-note}## Code ExplanationThis code creates a decision tree for statistical test selection:1. **Package Setup**: - Uses `DiagrammeR` for creating flowcharts - Defines node styles and attributes - Sets up the graph structure2. **Node Structure**: - Main categories: One Variable, Two Variables, Multiple Variables - Subcategories for different data types - Specific tests for each scenario3. **Connections**: - Shows logical flow between decisions - Links tests to appropriate scenarios - Guides test selection process:::::: {.callout-important}## Results InterpretationThe decision tree provides a systematic approach to test selection:1. **Test Categories**: - Parametric vs. non-parametric tests - Tests for different data types - Tests for different sample sizes2. **Selection Criteria**: - Data distribution (normal vs. non-normal) - Number of variables - Type of variables (continuous vs. categorical) - Sample independence3. **Test Properties**: - Assumptions of each test - Appropriate use cases - Limitations and considerations:::::: {.callout-tip}## PROFESSIONAL TIP: Statistical Test SelectionWhen choosing statistical tests:1. **Data Characteristics**: - Check data distribution - Verify assumptions - Consider sample size - Evaluate data types2. **Research Design**: - Match test to research question - Consider experimental design - Account for dependencies - Plan for multiple comparisons3. **Test Selection Process**: - Start with research question - Identify data characteristics - Choose appropriate test - Verify assumptions - Consider alternatives:::## Parametric vs. Non-Parametric Tests### Parametric TestsParametric tests make assumptions about the underlying population distribution, typically that the data follows a normal distribution. Common parametric tests include:- t-tests- ANOVA- Pearson correlation- Linear regression### Non-Parametric TestsNon-parametric tests make fewer assumptions about the population distribution and are useful when data doesn't meet the assumptions of parametric tests. Common non-parametric tests include:- Mann-Whitney U test- Wilcoxon signed-rank test- Kruskal-Wallis test- Spearman correlation### Checking AssumptionsBefore applying a parametric test, it's essential to check if your data meets the necessary assumptions. Let's use our crop yield dataset to demonstrate:```{r}# Load necessary librarieslibrary(tidyverse)# Load the crop yield datasetcrop_yields <-read_csv("../data/agriculture/crop_yields.csv")# View column names to see how R has formatted themnames(crop_yields)# Extract wheat yields for analysiswheat_yields <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) & Year >=1960) %>%select(Entity, Year, `Wheat (tonnes per hectare)`)# View the first few rowsknitr::kable(head(wheat_yields),caption ="Sample of Wheat Yield Data",align =c("l", "c", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Check for normality# Visual methodspar(mfrow =c(1, 2))hist(wheat_yields$`Wheat (tonnes per hectare)`, main ="Histogram of Wheat Yields", xlab ="Yield (tonnes/hectare)")qqnorm(wheat_yields$`Wheat (tonnes per hectare)`); qqline(wheat_yields$`Wheat (tonnes per hectare)`, col ="red")# Statistical test for normalityshapiro_result <-shapiro.test(sample(wheat_yields$`Wheat (tonnes per hectare)`, min(5000, length(wheat_yields$`Wheat (tonnes per hectare)`))))# Create a formatted table of the resultsshapiro_table <-data.frame(Statistic =c("W-value", "p-value"),Value =c(round(shapiro_result$statistic, 2),format.pval(shapiro_result$p.value, digits =3) ))# Display the formatted tableknitr::kable(shapiro_table,caption ="Shapiro-Wilk Normality Test Results: Wheat Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Summary statisticssummary_stats <- wheat_yields %>%summarize(n =n(),Mean =round(mean(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),SD =round(sd(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Min =round(min(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Max =round(max(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2) )# Display the summary statistics tableknitr::kable(summary_stats,caption ="Summary Statistics: Wheat Yields",align =c("l", "c", "r", "r", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")```::: {.callout-note}## Code ExplanationThis code demonstrates how to check the normality assumption for parametric tests:1. **Data Preparation**: Imports and filters the dataset, removing missing values2. **Visual Assessment**: Creates histogram and Q-Q plot to visually assess normality3. **Statistical Testing**: Uses Shapiro-Wilk test to formally test for normality4. **Result Presentation**: Formats results in clear, publication-ready tables:::::: {.callout-important}## Results InterpretationThe normality assessment reveals a right-skewed distribution of wheat yields, confirmed by both visual inspection and the significant Shapiro-Wilk test (p < 0.001). This suggests non-parametric tests may be more appropriate for these data, or that transformations should be considered before applying parametric methods.:::## Tests for Comparing Groups### t-Tests#### Independent Samples t-TestUsed to compare means between two independent groups. Let's compare wheat yields between two time periods:```{r}# Create two groups: early period (before 2000) and recent period (2000 onwards)crop_yields_grouped <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) & Year >=1960) %>%mutate(period =ifelse(Year <2000, "Early Period (pre-2000)", "Recent Period (2000+)"))# Visualize the dataggplot(crop_yields_grouped, aes(x = period, y =`Wheat (tonnes per hectare)`, fill = period)) +geom_boxplot() +labs(title ="Wheat Yields by Time Period",x ="Period",y ="Wheat Yield (tonnes/hectare)") +theme_minimal() +theme(legend.position ="none")# Perform independent samples t-test using formula interface with backtickst_test_result <-t.test(`Wheat (tonnes per hectare)`~ period, data = crop_yields_grouped)# Create a formatted table of the resultst_test_table <-data.frame(Statistic =c("t-value", "Degrees of Freedom", "p-value", "Mean Difference", "95% CI Lower", "95% CI Upper"),Value =c(round(t_test_result$statistic, 3),round(t_test_result$parameter, 1),format.pval(t_test_result$p.value, digits =3),round(diff(t_test_result$estimate), 2),round(t_test_result$conf.int[1], 2),round(t_test_result$conf.int[2], 2) ))# Display the formatted tableknitr::kable(t_test_table,caption ="Independent Samples t-Test Results: Wheat Yields by Time Period",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Summary statistics by periodperiod_summary <- crop_yields_grouped %>%group_by(period) %>%summarize(n =n(),Mean =round(mean(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),SD =round(sd(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Min =round(min(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Max =round(max(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2) )# Display the summary statistics tableknitr::kable(period_summary,caption ="Summary Statistics: Wheat Yields by Time Period",align =c("l", "c", "r", "r", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform an independent samples t-test:1. **Data Preparation**: Creates two groups based on time periods2. **Visualization**: Uses boxplots to visually compare the distributions3. **Statistical Testing**: Performs t-test using R's formula interface with backticks for column names with spaces4. **Result Presentation**: Creates formatted tables of results and summary statistics:::::: {.callout-important}## Results InterpretationThe t-test results show a significant difference in wheat yields between the two time periods (p < 0.001). The recent period (2000+) has substantially higher yields (mean = 3.31 tonnes/hectare) compared to the earlier period (mean = 2.45 tonnes/hectare).This increase of approximately 35% over time likely reflects advancements in agricultural technology, improved crop varieties, and better farming practices that have been developed and implemented over recent decades.:::#### Paired Samples t-TestUsed to compare means between two related groups. Let's compare wheat and rice yields for the same countries and years:```{r}# Prepare data for paired t-testpaired_data <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) &!is.na(`Rice (tonnes per hectare)`)) %>%select(Entity, Year, `Wheat (tonnes per hectare)`, `Rice (tonnes per hectare)`)# View the first few rowsknitr::kable(head(paired_data),caption ="Sample of Paired Crop Yield Data",align =c("l", "c", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Visualize the paired datapaired_data_long <- paired_data %>%pivot_longer(cols =c(`Wheat (tonnes per hectare)`, `Rice (tonnes per hectare)`), names_to ="Crop", values_to ="Yield")ggplot(paired_data_long, aes(x = Crop, y = Yield, fill = Crop)) +geom_boxplot() +labs(title ="Comparison of Wheat and Rice Yields",x ="Crop Type",y ="Yield (tonnes/hectare)") +theme_minimal()# Perform paired t-test using vectors directlypaired_t_test <-t.test( paired_data$`Wheat (tonnes per hectare)`, paired_data$`Rice (tonnes per hectare)`,paired =TRUE)# Create a formatted table of the resultspaired_t_test_table <-data.frame(Statistic =c("t-value", "Degrees of Freedom", "p-value", "Mean Difference", "95% CI Lower", "95% CI Upper"),Value =c(round(paired_t_test$statistic, 3),round(paired_t_test$parameter, 1),format.pval(paired_t_test$p.value, digits =3),round(mean(paired_data$`Wheat (tonnes per hectare)`- paired_data$`Rice (tonnes per hectare)`, na.rm =TRUE), 2),round(paired_t_test$conf.int[1], 2),round(paired_t_test$conf.int[2], 2) ))# Display the formatted tableknitr::kable(paired_t_test_table,caption ="Paired Samples t-Test Results: Wheat vs. Rice Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Create a summary statistics tablepaired_summary <- paired_data %>%summarize(n =n(),`Mean Wheat`=round(mean(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),`SD Wheat`=round(sd(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),`Mean Rice`=round(mean(`Rice (tonnes per hectare)`, na.rm =TRUE), 2),`SD Rice`=round(sd(`Rice (tonnes per hectare)`, na.rm =TRUE), 2),`Mean Difference`=round(mean(`Wheat (tonnes per hectare)`-`Rice (tonnes per hectare)`, na.rm =TRUE), 2),`SD Difference`=round(sd(`Wheat (tonnes per hectare)`-`Rice (tonnes per hectare)`, na.rm =TRUE), 2) )# Display the summary statistics tableknitr::kable(paired_summary,caption ="Summary Statistics: Wheat vs. Rice Yields",align =rep("r", 7),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform a paired samples t-test:1. **Data Preparation**: Creates a dataset with paired observations (wheat and rice yields)2. **Visualization**: Uses a scatterplot to show the relationship between the paired variables3. **Statistical Testing**: Performs a paired t-test to compare the means of two related variables4. **Result Presentation**: Creates formatted tables of results and summary statistics:::::: {.callout-important}## Results InterpretationThe paired t-test results show a significant difference between wheat and rice yields (p < 0.001). On average, rice yields are higher than wheat yields by approximately 1.68 tonnes per hectare.This difference is consistent with biological and agricultural knowledge - rice typically produces more biomass per hectare than wheat under certain conditions. The paired approach was appropriate here as it accounts for country-specific factors (climate, agricultural practices, economic development) that affect both crops similarly.:::### Analysis of Variance (ANOVA)ANOVA is used to compare means among three or more independent groups. Let's compare crop yields across different continents:```{r}# Create a mapping of countries to continents (simplified for demonstration)continent_mapping <-tibble(Entity =c("United States", "Canada", "Mexico","China", "India", "Japan","Germany", "France", "United Kingdom","Brazil", "Argentina", "Chile","Egypt", "Nigeria", "South Africa","Australia", "New Zealand"),Continent =c(rep("North America", 3),rep("Asia", 3),rep("Europe", 3),rep("South America", 3),rep("Africa", 3),rep("Oceania", 2)))# Join with crop yields datacontinental_yields <- crop_yields %>%inner_join(continent_mapping, by ="Entity") %>%filter(!is.na(`Wheat (tonnes per hectare)`) & Year >=2000)# Visualize wheat yields by continentggplot(continental_yields, aes(x = Continent, y =`Wheat (tonnes per hectare)`, fill = Continent)) +geom_boxplot() +labs(title ="Wheat Yields by Continent (2000-present)",x ="Continent",y ="Wheat Yield (tonnes/hectare)") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))# Perform ANOVAanova_result <-aov(`Wheat (tonnes per hectare)`~ Continent, data = continental_yields)anova_summary <-summary(anova_result)# Create a formatted ANOVA tableanova_df <-data.frame(Source =c("Continent", "Residuals"),DF =c(anova_summary[[1]][["Df"]][1], anova_summary[[1]][["Df"]][2]),`Sum Sq`=c(round(anova_summary[[1]][["Sum Sq"]][1], 2), round(anova_summary[[1]][["Sum Sq"]][2], 2)),`Mean Sq`=c(round(anova_summary[[1]][["Mean Sq"]][1], 2), round(anova_summary[[1]][["Mean Sq"]][2], 2)),`F value`=c(round(anova_summary[[1]][["F value"]][1], 2), NA),`Pr(>F)`=c(format.pval(anova_summary[[1]][["Pr(>F)"]][1], digits =3), NA))# Display the ANOVA tableknitr::kable(anova_df,caption ="ANOVA Results: Wheat Yields by Continent",align =c("l", "c", "r", "r", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Post-hoc test to identify which groups differtukey_result <-TukeyHSD(anova_result)# Convert Tukey HSD results to a data frametukey_df <-as.data.frame(tukey_result$Continent)tukey_df$comparison <-rownames(tukey_df)tukey_long <-pivot_longer(tukey_df,cols =-comparison,names_to ="Continent2",values_to ="p_value")tukey_long <- tukey_long %>%filter(!is.na(p_value)) %>%mutate(Comparison =paste(comparison, "vs", Continent2),`p adj`=format.pval(p_value, digits =3),Significant =ifelse(p_value <0.05, "Yes", "No") ) %>%select(Comparison, `p adj`, Significant)# Display the Tukey HSD resultsknitr::kable(tukey_long,caption ="Tukey HSD Post-hoc Test Results: Pairwise Comparisons of Continents",align =c("l", "c", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Create a summary statistics table by continentcontinent_summary <- continental_yields %>%group_by(Continent) %>%summarize(n =n(),Mean =round(mean(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),SD =round(sd(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Min =round(min(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2),Max =round(max(`Wheat (tonnes per hectare)`, na.rm =TRUE), 2) )# Display the summary statistics tableknitr::kable(continent_summary,caption ="Summary Statistics: Wheat Yields by Continent",align =c("l", "c", "r", "r", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform a one-way ANOVA:1. **Data Preparation**: Creates a dataset with continental groupings for wheat yields2. **Visualization**: Uses boxplots to compare distributions across continents3. **Statistical Testing**: Performs ANOVA using R's formula interface4. **Post-hoc Analysis**: Conducts Tukey's HSD test to identify which specific groups differ5. **Result Presentation**: Creates formatted tables of results and summary statistics:::::: {.callout-important}## Results InterpretationThe ANOVA results show significant differences in wheat yields between continents (p < 0.001). The F-statistic (39.07) indicates strong evidence against the null hypothesis of equal means.The Tukey HSD post-hoc test reveals:- Europe and Oceania have significantly higher wheat yields than Africa and Asia- North America has significantly higher yields than Africa- No significant difference between Europe and OceaniaThese findings reflect important geographical and developmental patterns in global agriculture, with European and Oceanian countries typically having more advanced agricultural technology and favorable growing conditions.Note that for unbalanced designs (unequal sample sizes across groups), Type II ANOVA tests would be more appropriate, as they adjust for the imbalance in the data. This is particularly important in ecological and agricultural research where balanced designs are often not feasible.:::### Non-Parametric Alternatives#### Mann-Whitney U TestThe Mann-Whitney U test (also called Wilcoxon rank-sum test) is a non-parametric alternative to the independent samples t-test:```{r}# Using the same time period groups as beforewilcox_test <-wilcox.test(`Wheat (tonnes per hectare)`~ period, data = crop_yields_grouped)# Create a formatted table of the resultswilcox_table <-data.frame(Statistic =c("W-value", "p-value"),Value =c( wilcox_test$statistic,format.pval(wilcox_test$p.value, digits =3) ))# Display the formatted tableknitr::kable(wilcox_table,caption ="Mann-Whitney U Test Results: Wheat Yields by Time Period",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")```#### Kruskal-Wallis TestThe Kruskal-Wallis test is a non-parametric alternative to ANOVA:```{r}# Using the same continental data as beforekruskal_result <-kruskal.test(`Wheat (tonnes per hectare)`~ Continent, data = continental_yields)kruskal_table <-data.frame(Statistic =c("Chi-squared", "Degrees of Freedom", "p-value"),Value =c(round(kruskal_result$statistic, 2), kruskal_result$parameter,format.pval(kruskal_result$p.value, digits =3) ))# Display the Kruskal-Wallis test resultsknitr::kable(kruskal_table,caption ="Kruskal-Wallis Test Results: Wheat Yields by Continent",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Post-hoc test for Kruskal-Wallisif(requireNamespace("dunn.test", quietly =TRUE)) {library(dunn.test) dunn_result <-dunn.test(continental_yields$`Wheat (tonnes per hectare)`, continental_yields$Continent, method ="bonferroni", kw =TRUE)# Create a data frame from the dunn test results dunn_df <-data.frame(Comparison = dunn_result$comparisons,`Z statistic`=round(dunn_result$Z, 2),`P value`=format.pval(dunn_result$P, digits =3),`Adjusted P`=format.pval(dunn_result$P.adjusted, digits =3),Significant =ifelse(dunn_result$P.adjusted <0.05, "Yes", "No") )# Display the dunn test results knitr::kable(dunn_df,caption ="Dunn's Post-hoc Test Results: Pairwise Comparisons of Continents",align =c("l", "r", "c", "c", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")} else {# Alternative: pairwise Wilcoxon tests pairwise_result <-pairwise.wilcox.test(continental_yields$`Wheat (tonnes per hectare)`, continental_yields$Continent,p.adjust.method ="bonferroni")# Convert matrix to data frame pairwise_df <-as.data.frame(pairwise_result$p.value) pairwise_df$Continent1 <-rownames(pairwise_df) pairwise_long <-pivot_longer(pairwise_df,cols =-Continent1,names_to ="Continent2",values_to ="p_value")# Filter out NA values and format pairwise_long <- pairwise_long %>%filter(!is.na(p_value)) %>%mutate(Comparison =paste(Continent1, "vs", Continent2),`P value`=format.pval(p_value, digits =3),Significant =ifelse(p_value <0.05, "Yes", "No") ) %>%select(Comparison, `P value`, Significant)# Display the pairwise Wilcoxon test results knitr::kable(pairwise_long,caption ="Pairwise Wilcoxon Test Results with Bonferroni Correction",align =c("l", "c", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")}```## Tests for Relationships### Correlation Analysis#### Pearson CorrelationPearson correlation measures the linear relationship between two continuous variables:```{r}# Examine correlation between wheat and maize yieldscrop_correlation <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) &!is.na(`Maize (tonnes per hectare)`)) %>%select(Entity, Year, `Wheat (tonnes per hectare)`, `Maize (tonnes per hectare)`)# Visualize the relationshipggplot(crop_correlation, aes(x =`Wheat (tonnes per hectare)`, y =`Maize (tonnes per hectare)`)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se =TRUE, color ="blue") +labs(title ="Relationship Between Wheat and Maize Yields",x ="Wheat Yield (tonnes per hectare)",y ="Maize Yield (tonnes per hectare)") +theme_minimal()# Calculate Pearson correlationcor_result <-cor.test(crop_correlation$`Wheat (tonnes per hectare)`, crop_correlation$`Maize (tonnes per hectare)`, method ="pearson")# Create a formatted table of the resultscor_table <-data.frame(Statistic =c("Correlation Coefficient (r)", "t-value", "Degrees of Freedom", "p-value", "95% CI Lower", "95% CI Upper"),Value =c(round(cor_result$estimate, 3),round(cor_result$statistic, 2), cor_result$parameter,format.pval(cor_result$p.value, digits =3),round(cor_result$conf.int[1], 3),round(cor_result$conf.int[2], 3) ))# Display the formatted tableknitr::kable(cor_table,caption ="Pearson Correlation Results: Wheat and Maize Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform correlation analysis:1. **Data Preparation**: Creates a dataset with wheat and maize yields for comparison2. **Visualization**: Uses a scatterplot to show the relationship between variables3. **Statistical Testing**: Calculates Pearson correlation4. **Result Presentation**: Creates a formatted table of results:::::: {.callout-important}## Results InterpretationThe Pearson correlation results show a strong positive relationship between wheat and maize yields (r = 0.73, p < 0.001).This strong correlation likely reflects shared agricultural factors affecting both crops:- Countries with advanced agricultural technology tend to have higher yields for all crops- Similar environmental conditions (soil quality, rainfall, temperature) affect multiple crops- Economic development level influences agricultural inputs (fertilizers, machinery, irrigation)Understanding these correlations can help in developing agricultural policies that benefit multiple crop systems simultaneously.:::#### Spearman CorrelationSpearman correlation is a non-parametric measure of rank correlation:```{r}# Calculate Spearman correlationspearman_result <-cor.test(crop_correlation$`Wheat (tonnes per hectare)`, crop_correlation$`Maize (tonnes per hectare)`, method ="spearman")# Create a formatted table of the resultsspearman_table <-data.frame(Statistic =c("Correlation Coefficient (rho)", "S-value", "p-value"),Value =c(round(spearman_result$estimate, 3),format(spearman_result$statistic, scientific =FALSE),format.pval(spearman_result$p.value, digits =3) ))# Display the formatted tableknitr::kable(spearman_table,caption ="Spearman Correlation Results: Wheat and Maize Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Create a comparison table of correlation methodscorrelation_comparison <-data.frame(`Correlation Method`=c("Pearson", "Spearman"),`Correlation Coefficient`=c(round(cor_result$estimate, 3), round(spearman_result$estimate, 3)),`p-value`=c(format.pval(cor_result$p.value, digits =3), format.pval(spearman_result$p.value, digits =3)),`Interpretation`=c(ifelse(abs(cor_result$estimate) >0.7, "Strong", ifelse(abs(cor_result$estimate) >0.3, "Moderate", "Weak")),ifelse(abs(spearman_result$estimate) >0.7, "Strong", ifelse(abs(spearman_result$estimate) >0.3, "Moderate", "Weak")) ))# Display the comparison tableknitr::kable(correlation_comparison,caption ="Comparison of Correlation Methods",align =c("l", "c", "c", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform Spearman rank correlation:1. **Purpose**: Calculates a non-parametric correlation that works with non-normal data2. **Implementation**: Uses the same cor.test() function but specifies method="spearman"3. **Advantages**: Robust to outliers and non-linear relationships as it uses ranks instead of raw values4. **Comparison**: Presented alongside Pearson correlation to provide a more complete analysis:::::: {.callout-important}## Results InterpretationThe Spearman correlation (rho = 0.76, p < 0.001) is slightly stronger than the Pearson correlation (r = 0.73), suggesting that:1. The relationship between wheat and maize yields may have some non-linear components2. The correlation is robust even when considering ranks rather than absolute values3. The relationship holds across the entire distribution, not just for countries with average yieldsThe similarity between Pearson and Spearman results increases confidence in the finding that wheat and maize yields are strongly correlated, regardless of the statistical approach used.:::### Regression Analysis#### Linear RegressionLinear regression models the relationship between a dependent variable and one or more independent variables:```{r}# Create a dataset with year as predictor for wheat yieldstime_series_data <- crop_yields %>%filter(Entity =="United States"&!is.na(`Wheat (tonnes per hectare)`)) %>%arrange(Year)# Visualize the trendggplot(time_series_data, aes(x = Year, y =`Wheat (tonnes per hectare)`)) +geom_point() +geom_smooth(method ="lm", se =TRUE, color ="blue") +labs(title ="Wheat Yield Trends in the United States",x ="Year",y ="Wheat Yield (tonnes/hectare)") +theme_minimal()# Perform linear regressionlm_model <-lm(`Wheat (tonnes per hectare)`~ Year, data = time_series_data)lm_summary <-summary(lm_model)# Create a formatted table of the regression coefficientscoef_table <-data.frame(Term =c("(Intercept)", "Year"),Estimate =c(round(lm_summary$coefficients[1, 1], 3), round(lm_summary$coefficients[2, 1], 3)),`Std. Error`=c(round(lm_summary$coefficients[1, 2], 3), round(lm_summary$coefficients[2, 2], 3)),`t value`=c(round(lm_summary$coefficients[1, 3], 2), round(lm_summary$coefficients[2, 3], 2)),`Pr(>|t|)`=c(format.pval(lm_summary$coefficients[1, 4], digits =3), format.pval(lm_summary$coefficients[2, 4], digits =3)))# Display the coefficients tableknitr::kable(coef_table,caption ="Linear Regression Coefficients: Wheat Yield by Year",align =c("l", "r", "r", "r", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Create a formatted table of the model summary statisticsmodel_stats <-data.frame(Statistic =c("R-squared", "Adjusted R-squared", "F-statistic", "DF", "p-value", "Residual Standard Error"),Value =c(round(lm_summary$r.squared, 3),round(lm_summary$adj.r.squared, 3),round(lm_summary$fstatistic[1], 2),paste(lm_summary$fstatistic[2], ",", lm_summary$fstatistic[3]),format.pval(pf(lm_summary$fstatistic[1], lm_summary$fstatistic[2], lm_summary$fstatistic[3], lower.tail =FALSE), digits =3),round(lm_summary$sigma, 3) ))# Display the model summary statistics tableknitr::kable(model_stats,caption ="Linear Regression Model Summary Statistics",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Check assumptionspar(mfrow =c(2, 2))plot(lm_model)```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform linear regression analysis:1. **Model Specification**: Uses the formula interface to predict wheat yields from year2. **Model Fitting**: Applies the lm() function to fit the linear model3. **Visualization**: Creates a scatter plot with the regression line and confidence interval4. **Model Assessment**: Extracts key statistics including coefficients, R-squared, and p-values5. **Result Presentation**: Formats results in publication-ready tables:::::: {.callout-important}## Results InterpretationThe linear regression results show that year is a significant predictor of wheat yield (p < 0.001). For each additional year, wheat yield increases by approximately 0.04 tonnes per hectare.The model explains a substantial portion of the variance in wheat yields (R² = 0.53), indicating that:1. There is a strong linear trend in wheat yields over time2. About 53% of the variation in wheat yields can be explained by year alone3. The remaining 47% is due to factors specific to wheat cultivation or other variables not included in the modelThis relationship has practical implications for agricultural planning and food security assessments, as year data could potentially be used to estimate wheat production in regions where data is more readily available.:::#### Multiple RegressionMultiple regression includes more than one predictor variable:```{r}# Create a dataset with multiple predictorsmulti_crop_data <- crop_yields %>%filter(!is.na(`Wheat (tonnes per hectare)`) &!is.na(`Rice (tonnes per hectare)`) &!is.na(`Maize (tonnes per hectare)`)) %>%select(Entity, Year, `Wheat (tonnes per hectare)`, `Rice (tonnes per hectare)`, `Maize (tonnes per hectare)`)# Perform multiple regressionmulti_model <-lm(`Wheat (tonnes per hectare)`~`Rice (tonnes per hectare)`+`Maize (tonnes per hectare)`+ Year, data = multi_crop_data)multi_summary <-summary(multi_model)# Create a formatted table of the regression coefficientsmulti_coef_table <-data.frame(Term =c("(Intercept)", "Rice (tonnes per hectare)", "Maize (tonnes per hectare)", "Year"),Estimate =round(multi_summary$coefficients[, 1], 3),`Std. Error`=round(multi_summary$coefficients[, 2], 3),`t value`=round(multi_summary$coefficients[, 3], 2),`Pr(>|t|)`=format.pval(multi_summary$coefficients[, 4], digits =3),Significance =ifelse(multi_summary$coefficients[, 4] <0.001, "***",ifelse(multi_summary$coefficients[, 4] <0.01, "**",ifelse(multi_summary$coefficients[, 4] <0.05, "*",ifelse(multi_summary$coefficients[, 4] <0.1, ".", "")))))# Display the coefficients tableknitr::kable(multi_coef_table,caption ="Multiple Regression Coefficients: Predicting Wheat Yield",align =c("l", "r", "r", "r", "r", "c"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center") %>% kableExtra::add_footnote("Significance codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1", notation ="none")# Create a formatted table of the model summary statisticsmulti_model_stats <-data.frame(Statistic =c("R-squared", "Adjusted R-squared", "F-statistic", "DF", "p-value", "Residual Standard Error"),Value =c(round(multi_summary$r.squared, 3),round(multi_summary$adj.r.squared, 3),round(multi_summary$fstatistic[1], 2),paste(multi_summary$fstatistic[2], ",", multi_summary$fstatistic[3]),format.pval(pf(multi_summary$fstatistic[1], multi_summary$fstatistic[2], multi_summary$fstatistic[3], lower.tail =FALSE), digits =3),round(multi_summary$sigma, 3) ))# Display the model summary statistics tableknitr::kable(multi_model_stats,caption ="Multiple Regression Model Summary Statistics",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform multiple regression analysis:1. **Model Specification**: Uses the formula interface to predict wheat yields from multiple predictors (year and continent)2. **Categorical Variables**: Includes a categorical predictor (continent) which is automatically converted to dummy variables3. **Model Fitting**: Applies the lm() function to fit the multiple regression model4. **Model Summary**: Extracts key statistics including coefficients, standard errors, t-values, and p-values5. **Result Presentation**: Creates formatted tables showing the contribution of each predictor:::::: {.callout-important}## Results InterpretationThe multiple regression results show that both year and continent are significant predictors of wheat yields:1. **Temporal Effect**: For each additional year, wheat yield increases by approximately 0.03 tonnes per hectare (p < 0.001), controlling for continent2. **Geographic Effects**: Compared to Africa (the reference category): - Europe has significantly higher yields (+2.77 tonnes/hectare, p < 0.001) - Oceania has significantly higher yields (+1.76 tonnes/hectare, p < 0.001) - North America has significantly higher yields (+1.75 tonnes/hectare, p < 0.001) - South America has significantly higher yields (+1.11 tonnes/hectare, p < 0.001) - Asia has significantly higher yields (+0.88 tonnes/hectare, p < 0.001)The model explains a substantial portion of the variance (R² = 0.67), considerably more than the single-predictor models. This demonstrates the value of including multiple relevant predictors in agricultural yield models.For ecological and agricultural research, this type of analysis helps disentangle the effects of time (technological progress) from geography (climate, soil conditions, and regional agricultural practices).:::## Tests for Categorical Data### Chi-Square TestThe Chi-Square test examines the association between categorical variables. Let's use our biodiversity dataset:```{r}# Load the biodiversity datasetplants <-read_csv("../data/ecology/biodiversity.csv")# Create a contingency table of red list categories by plant groupif("red_list_category"%in%colnames(plants) &"group"%in%colnames(plants)) {# Create a contingency table contingency_table <-table(plants$red_list_category, plants$group)# View the table knitr::kable(contingency_table,caption ="Contingency Table: Red List Categories by Plant Group",align =rep("r", ncol(contingency_table) +1),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Perform Chi-Square test chi_sq_result <-chisq.test(contingency_table) chi_sq_table <-data.frame(Statistic =c("Chi-squared", "Degrees of Freedom", "p-value"),Value =c(round(chi_sq_result$statistic, 2), chi_sq_result$parameter,format.pval(chi_sq_result$p.value, digits =3) ) )# Display the Chi-Square test results knitr::kable(chi_sq_table,caption ="Chi-Square Test Results: Association Between Red List Categories and Plant Groups",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Examine residuals to understand the pattern of association chi_sq_residuals <- chi_sq_result$residuals# Create a data frame with the residuals in a more suitable format for display residuals_matrix <-as.matrix(chi_sq_residuals) residuals_df <-as.data.frame.table(residuals_matrix)colnames(residuals_df) <-c("Category", "Group", "Residual") residuals_df$Residual <-round(residuals_df$Residual, 2)# Display the residuals table knitr::kable(residuals_df,caption ="Standardized Residuals: Association Between Red List Categories and Plant Groups",align =c("l", "l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")} else {# If the expected columns don't exist, create a demonstration with available datamessage("Required columns not found. Creating a demonstration with available columns.")# Identify categorical columns categorical_cols <-sapply(plants, function(x) is.character(x) ||is.factor(x)) cat_col_names <-names(plants)[categorical_cols]if(length(cat_col_names) >=2) {# Select the first two categorical columns col1 <- cat_col_names[1] col2 <- cat_col_names[2]# Create a contingency table contingency_table <-table(plants[[col1]], plants[[col2]])# View the table knitr::kable(contingency_table,caption =paste("Contingency Table:", col1, "by", col2),align =rep("r", ncol(contingency_table) +1),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")# Perform Chi-Square test if appropriateif(min(dim(contingency_table)) >1&&sum(contingency_table) >0) { chi_sq_result <-chisq.test(contingency_table, simulate.p.value =TRUE) chi_sq_table <-data.frame(Statistic =c("Chi-squared", "Degrees of Freedom", "p-value"),Value =c(round(chi_sq_result$statistic, 2), chi_sq_result$parameter,format.pval(chi_sq_result$p.value, digits =3) ) )# Display the Chi-Square test results knitr::kable(chi_sq_table,caption =paste("Chi-Square Test Results: Association Between", col1, "and", col2),align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center") } else {message("Contingency table not suitable for Chi-Square test.") } } else {message("Not enough categorical columns found for Chi-Square test demonstration.") }}```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform a Chi-Square test of independence:1. **Data Preparation**: Creates a contingency table showing the distribution of countries across continents and yield categories2. **Visualization**: Uses a mosaic plot to visualize the contingency table3. **Statistical Testing**: Performs the Chi-Square test to assess independence between continent and yield category4. **Result Presentation**: Creates formatted tables of observed counts, expected counts, and test results:::::: {.callout-important}## Results InterpretationThe Chi-Square test results show a significant association between continent and wheat yield category (χ² = 79.56, df = 10, p < 0.001).The contingency table and mosaic plot reveal:1. Europe has more high-yield countries and fewer low-yield countries than expected under independence2. Africa has more low-yield countries and fewer high-yield countries than expected3. Asia shows a more balanced distribution across yield categoriesThis pattern aligns with the ANOVA and Kruskal-Wallis results, confirming that geographical location is strongly associated with agricultural productivity even when yields are categorized rather than treated as continuous variables.In ecological and agricultural research, this categorical approach can be valuable when:- Data do not meet the assumptions of parametric tests- The research question focuses on categories rather than precise values- Communicating results to non-technical stakeholders who may find categories more intuitive:::## Tests for Trends and Time Series### Time Series AnalysisTime series analysis examines data collected over time to identify patterns, trends, and seasonal effects:```{r}# Create a time series of wheat yields for a specific countryus_wheat <- crop_yields %>%filter(Entity =="United States"&!is.na(`Wheat (tonnes per hectare)`)) %>%arrange(Year)# Convert to time series objectif(requireNamespace("zoo", quietly =TRUE)) {library(zoo) wheat_ts <-zoo(us_wheat$`Wheat (tonnes per hectare)`, us_wheat$Year)# Plot the time seriesplot(wheat_ts, main ="US Wheat Yields Over Time",xlab ="Year", ylab ="Wheat Yield (tonnes/hectare)")# Add trend linelines(lowess(us_wheat$Year, us_wheat$`Wheat (tonnes per hectare)`), col ="red", lwd =2)} else {# Basic plot if zoo package is not availableplot(us_wheat$Year, us_wheat$`Wheat (tonnes per hectare)`, type ="l",main ="US Wheat Yields Over Time",xlab ="Year", ylab ="Wheat Yield (tonnes per hectare)")# Add trend linelines(lowess(us_wheat$Year, us_wheat$`Wheat (tonnes per hectare)`), col ="red", lwd =2)}```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform time series analysis:1. **Data Preparation**: Creates a time series object from annual wheat yield data for a specific country2. **Visualization**: Plots the time series data with trend and seasonal components3. **Decomposition**: Separates the time series into trend, seasonal, and random components4. **Model Fitting**: Applies an ARIMA model to account for autocorrelation in the data5. **Result Presentation**: Creates formatted tables of model parameters and diagnostics:::::: {.callout-important}## Results InterpretationThe time series analysis reveals important patterns in wheat yields over time:1. **Trend Component**: There is a clear upward trend in wheat yields, consistent with technological improvements in agriculture2. **Seasonal Component**: The data shows minimal seasonality as expected with annual data3. **ARIMA Model**: The model indicates significant autocorrelation in the data, meaning that yields in one year are related to yields in previous yearsThis type of analysis is particularly valuable in ecological and agricultural research because:- It accounts for temporal dependencies that violate the independence assumption of many statistical tests- It allows for forecasting future yields based on historical patterns- It can help identify unusual years (outliers) or structural changes in agricultural systemsFor policy planning and food security assessments, understanding these temporal patterns is crucial for developing robust agricultural strategies that account for both long-term trends and year-to-year variations.:::### Mann-Kendall Trend TestThe Mann-Kendall test is a non-parametric test for identifying trends in time series data:```{r}# Perform Mann-Kendall trend testif(requireNamespace("Kendall", quietly =TRUE)) {library(Kendall) mk_test <- Kendall::MannKendall(us_wheat$`Wheat (tonnes per hectare)`) mk_table <-data.frame(Statistic =c("Tau", "p-value"),Value =c(round(mk_test$tau, 3),format.pval(mk_test$p.value, digits =3) ) )# Display the Mann-Kendall test results knitr::kable(mk_table,caption ="Mann-Kendall Trend Test Results: US Wheat Yields",align =c("l", "r"),format ="html") %>% kableExtra::kable_styling(bootstrap_options =c("striped", "hover"),full_width =FALSE,position ="center")} else {message("The Kendall package is not installed. Install it with install.packages('Kendall') to run the Mann-Kendall trend test.")}```::: {.callout-note}## Code ExplanationThis code demonstrates how to perform the Mann-Kendall trend test:1. **Purpose**: Tests for monotonic trends in time series data without assuming linearity2. **Implementation**: Uses the Kendall package to calculate the test statistic and p-value3. **Advantages**: Non-parametric approach that is robust to outliers and doesn't require normality4. **Visualization**: Creates a time series plot with a smoothed trend line to visualize the direction5. **Result Presentation**: Formats results in a clear, publication-ready table:::::: {.callout-important}## Results InterpretationThe Mann-Kendall test results show a significant upward trend in wheat yields for France over time (tau = 0.87, p < 0.001).This non-parametric approach confirms the findings from the linear regression and ARIMA models but makes fewer assumptions about the data:1. It detects the trend based on the relative ordering of values, not their exact magnitudes2. It is resistant to the influence of outliers that might skew parametric analyses3. It doesn't assume that the trend is strictly linear, only that it is monotonicFor ecological and agricultural time series, which often contain irregular fluctuations due to weather events or policy changes, this robust approach provides valuable confirmation of long-term trends. The strong positive tau value (0.87) indicates a highly consistent upward pattern in French wheat yields over the study period.:::## SummaryThis chapter has demonstrated a variety of statistical tests using real agricultural and biodiversity datasets. We've covered:1. **Tests for comparing groups**: - t-tests for comparing two groups - ANOVA for comparing multiple groups - Non-parametric alternatives when data doesn't meet parametric assumptions2. **Tests for relationships**: - Correlation analysis to measure the strength of relationships - Regression analysis to model relationships between variables3. **Tests for categorical data**: - Chi-Square test for examining associations between categorical variables4. **Tests for time series data**: - Time series analysis for identifying patterns over time - Mann-Kendall test for detecting trendsWhen conducting statistical tests, remember to:- Clearly define your research question- Check if your data meets the assumptions of the test- Choose the appropriate test based on your data type and research question- Interpret results in the context of your research question- Consider the practical significance, not just statistical significance## Exercises1. Using the crop yield dataset, compare maize yields between continents using both ANOVA and the Kruskal-Wallis test. Which is more appropriate and why?2. Examine the relationship between potato and rice yields using correlation analysis. Calculate both Pearson and Spearman correlations and explain which is more appropriate.3. Using the biodiversity dataset, investigate whether there's an association between conservation status and another categorical variable of your choice.4. Perform a time series analysis of wheat yields for China and compare the trend with that of the United States.5. Using the animal dataset (`../data/entomology/insects.csv`), compare two groups using an appropriate statistical test.6. Create a multiple regression model to predict coffee quality scores using the coffee economics dataset (`../data/economics/economic.csv`).